配置连接
1.运行ssh-keygen -f key -N ''命令,这会在当前目录下生成key和key.pub文件,分别是公钥和私钥。
2.cat key.pub打印key.pub文件内容。
3.将打印出的内容复制粘贴到Settings->SSH Key中。
4.ssh -i key hacker@dojo.pwn.college连接至靶机
ssh -i key hacker@dojo.pwn.college
视频内容
intro

这个过程中,信息总会丢失一些,所以逆向就是挖掘这些

前向工程工具

编译过程中会删除掉所有的宏定义,注释,之后生成汇编代码,并且替换掉了变量,用地址和偏移进行替换,通过strip 命令,可以移除调试符号和其他不必要的信息,从而减少文件大小并且提高加载效率,
gcc -g可以包括所有的,包括像类型,变量名变量大小等调试信息
function and frames



函数其实可以被表示为一个图,每一个块都是将一条条执行的指令,然后块被边连接着,也就是各种条件或者无条件跳转,之后通过理解这些触发跳转的条件,来理解函数逻辑
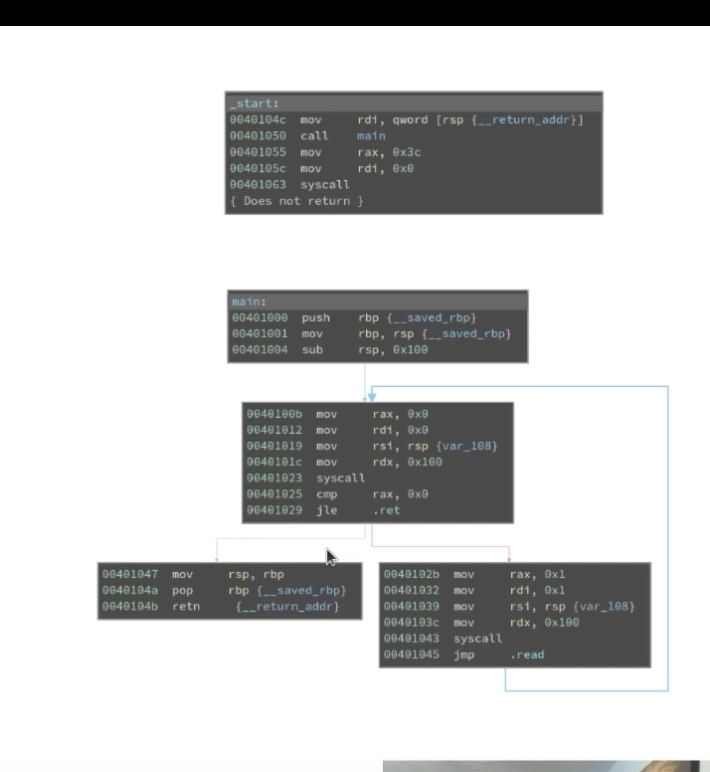
蓝线代表着无条件跳转,绿线代表着条件跳转,
栈

局部变量放在了栈上面,
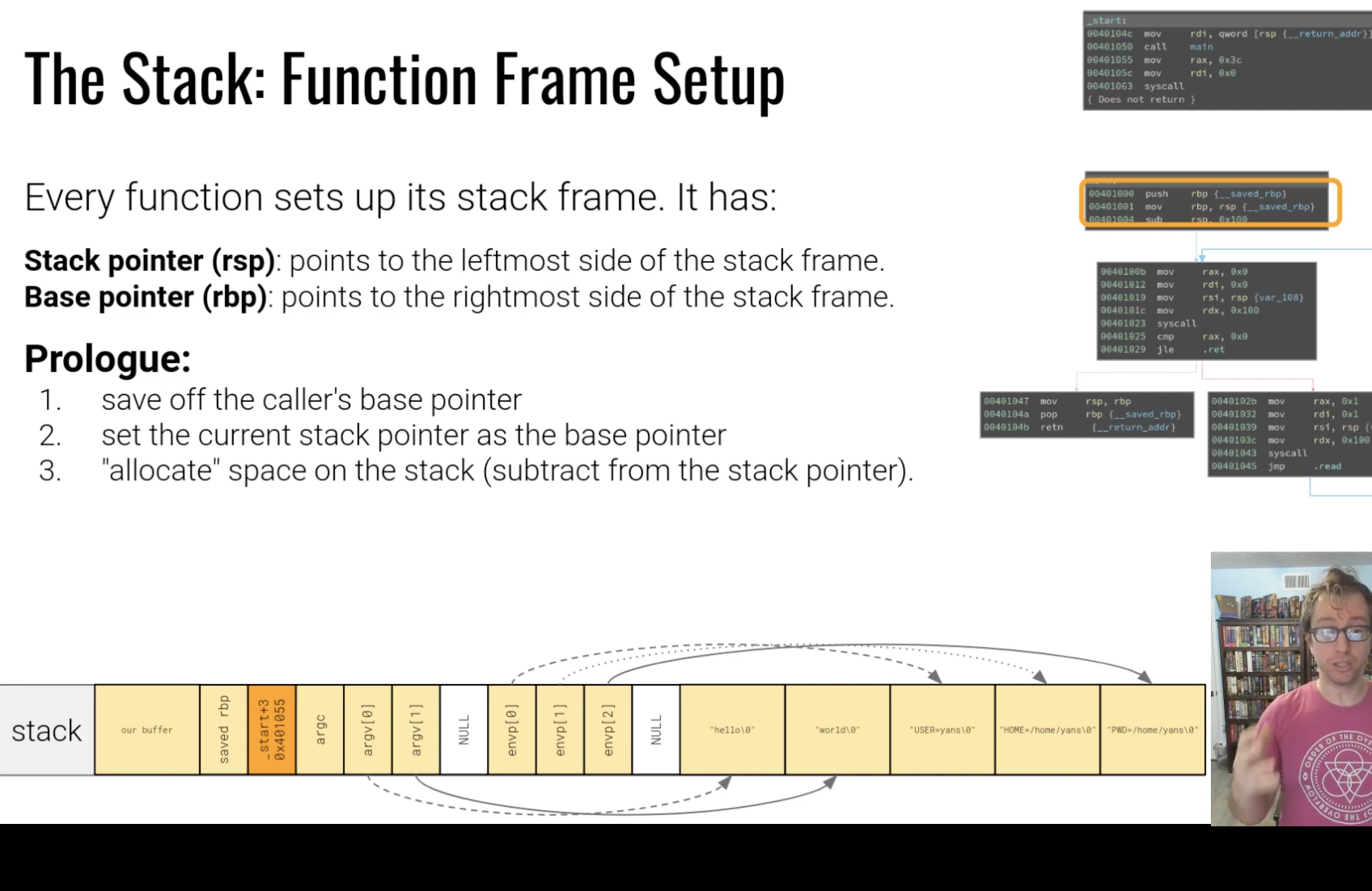
call之后先压栈下一条指令的地址,之后存储rbp,
退栈不物理清除数据,因此可能导致数据泄漏,

data access

栈上的数据

elf节中的变量

这些一般都和指令有固定的偏移,通常通过rip 相对寻址去进行访问

会发现,程序被映射到内存中两次,一次是代码,一次是用于数据段,因此,代码和数据是从两个不同的区域进行访问的,
堆中的数据
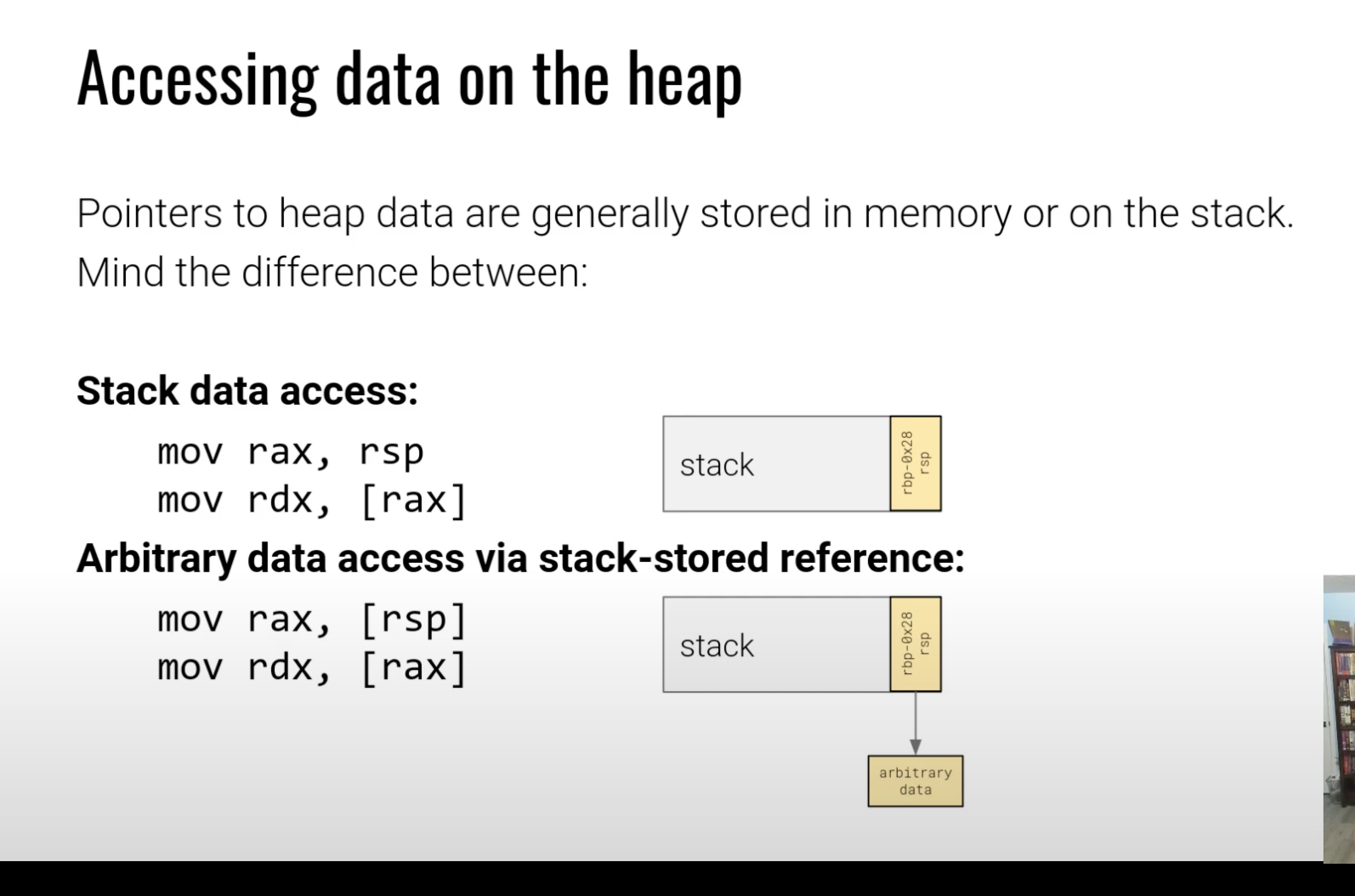
访问堆的指针通常存放在栈上,第一个存放在栈上的是数据,直接取出来rsp,rsp相当于是他的地址,之后解引用就可以获得数据,而第二个相当于将访问数据的指针存放在了栈上,获取到指针之后还需要堆指针进行进一步的解引用才能获取到后续的数据
数据结构

获得该类数据你需要知道他都有什么东西,然后怎么存储的,怎么访问的怎么使用的,然后才能逆向出正确的数据
静态逆向工具
指的是,不运行的时候就能分析的工具,

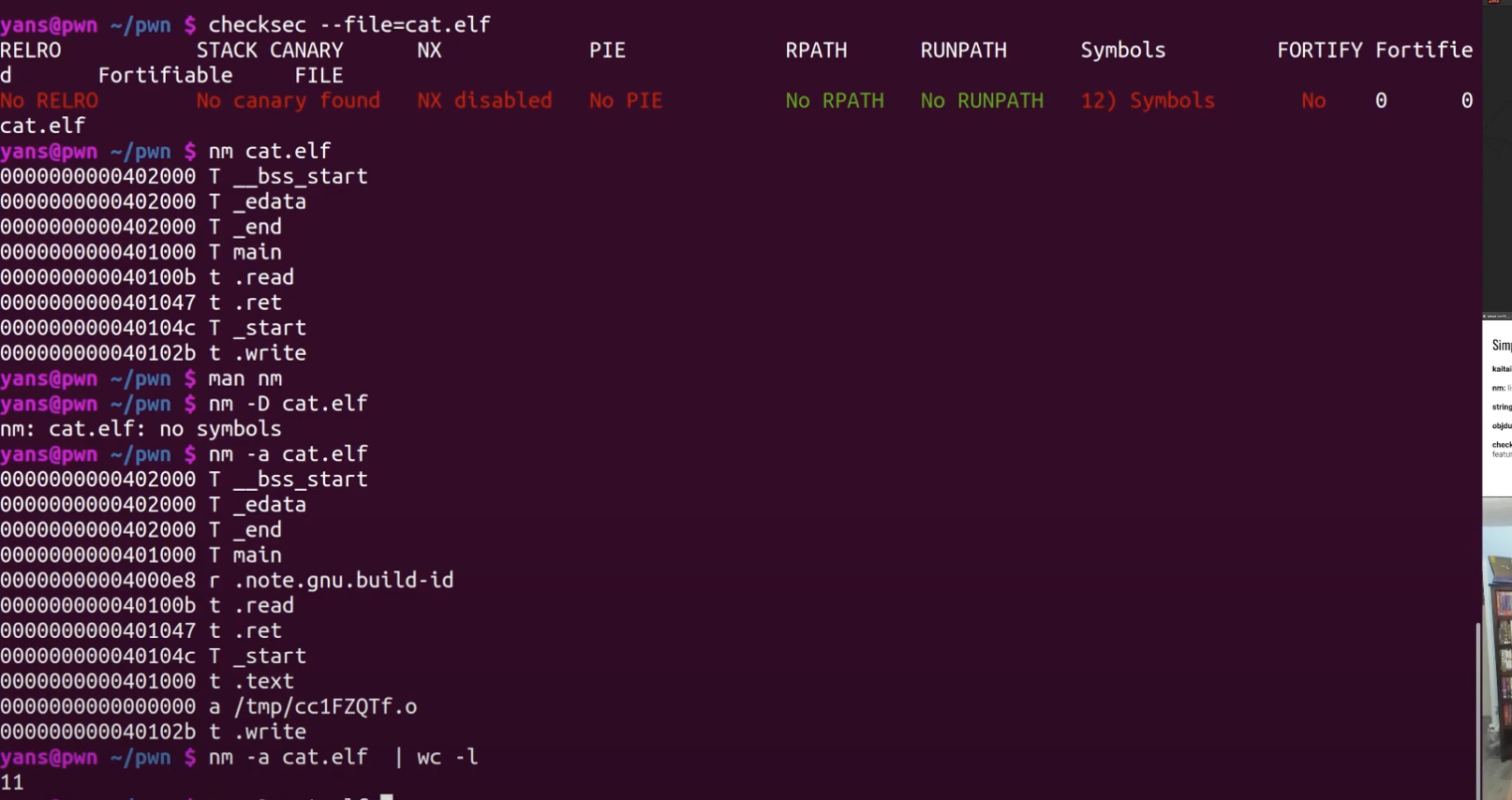
比如checksec后发现了有12个符号,之后通过nm -a来列举所有的符号,

课程里用的binary ninja cloud,免费
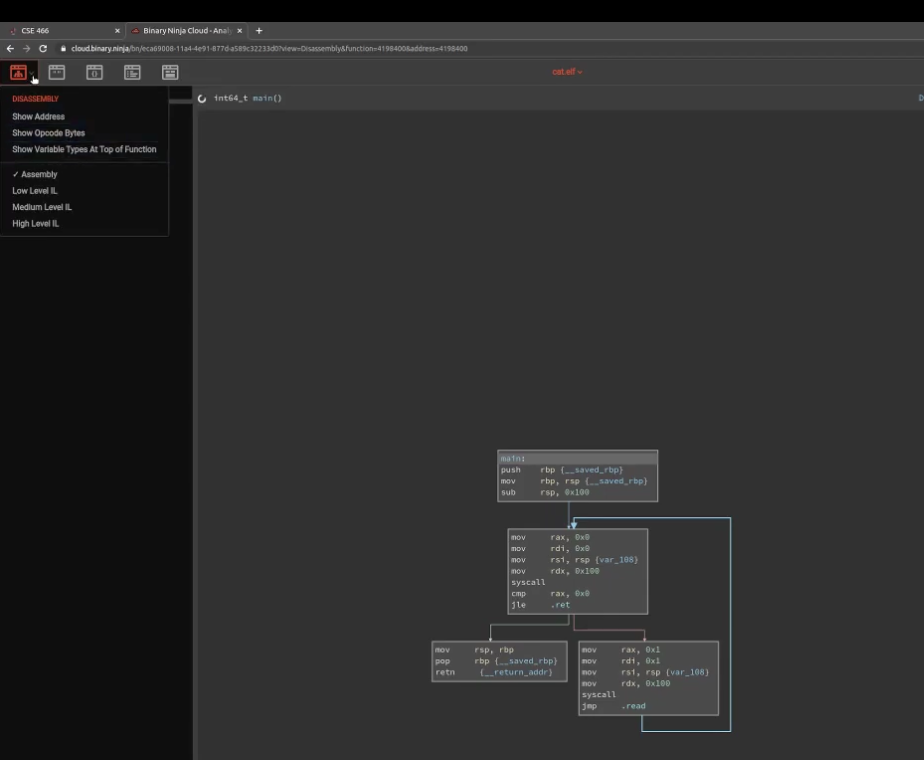
左上角这里,这里可以显示更多的信息,包括指令详细的操作码字节等等,
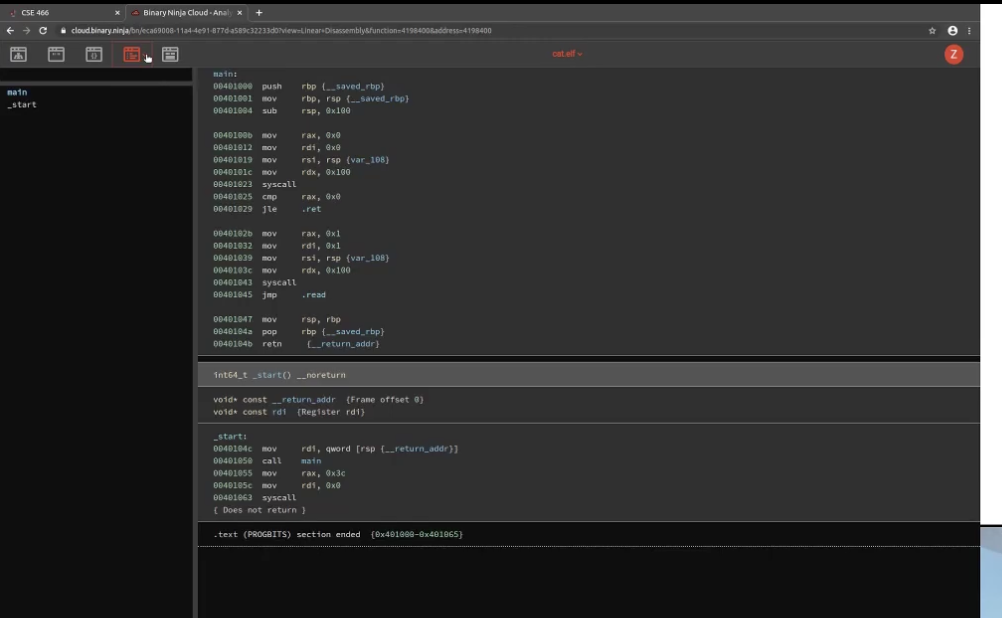
这里可以显示更熟悉的线性的界面,右键指令可以进行注释
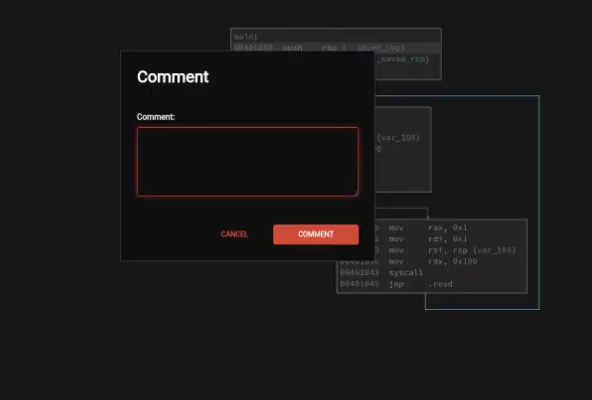
这里的高级分析,能够分析的更加详细,并且进行反编译,
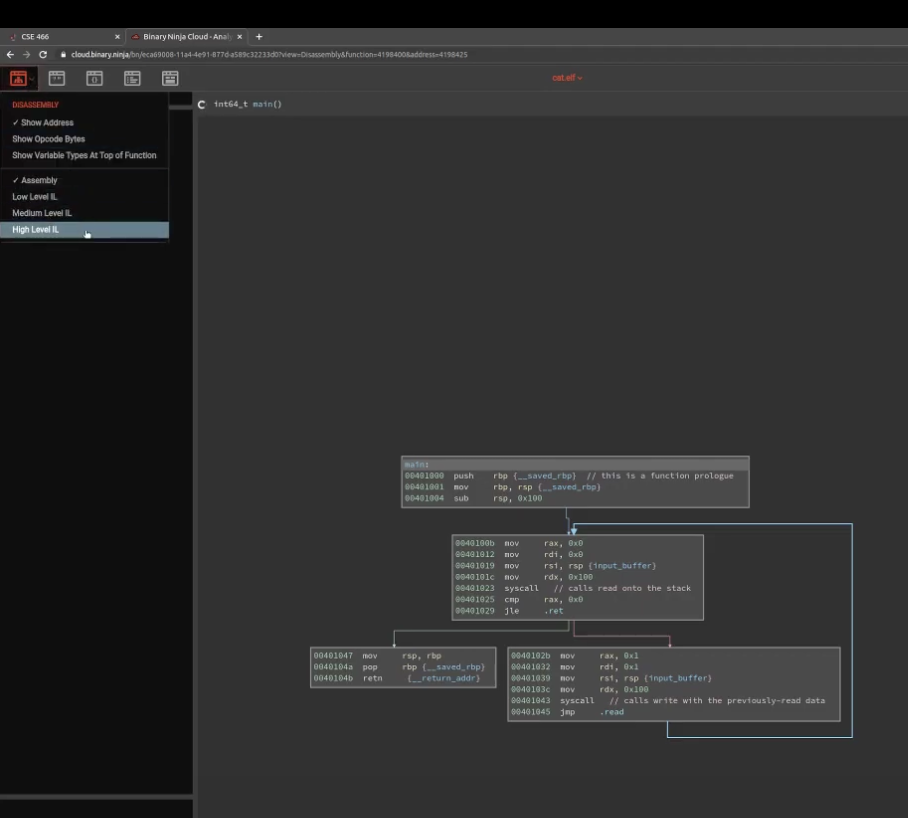
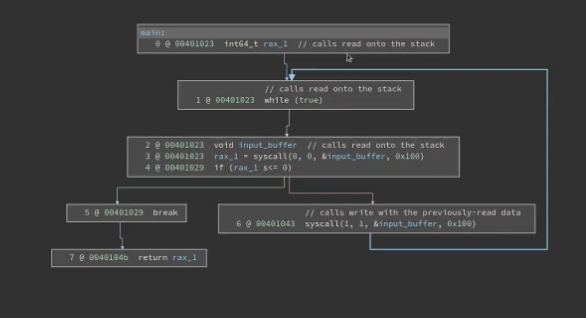
但是他有可能抽象错细节,所以在这个课程里最好还是只用汇编视图
Dynamic

一个是追踪库调用,一个是追踪系统调用
强烈建议加入init文件的
info proc map,能够查看映射的地址

位置相关代码始终加载在同一个内存位置,但是内存无关代码并不是,gdb尝试永远在这个范围加载,最简单的就是通过set $base

通过-M可以指定汇编类型

gdb自带的重放比较低效,因此,rr更高效,但pwncollege不能用rr,kira比较简洁,用于逆向工程,还有reverse step in,rsi,会反向进行移动,前提是前面进行了record,但是有时候不准,当再次进行录音的时候,不会再次系统调用,只是重播录音
real world app
challenge
Level1.0
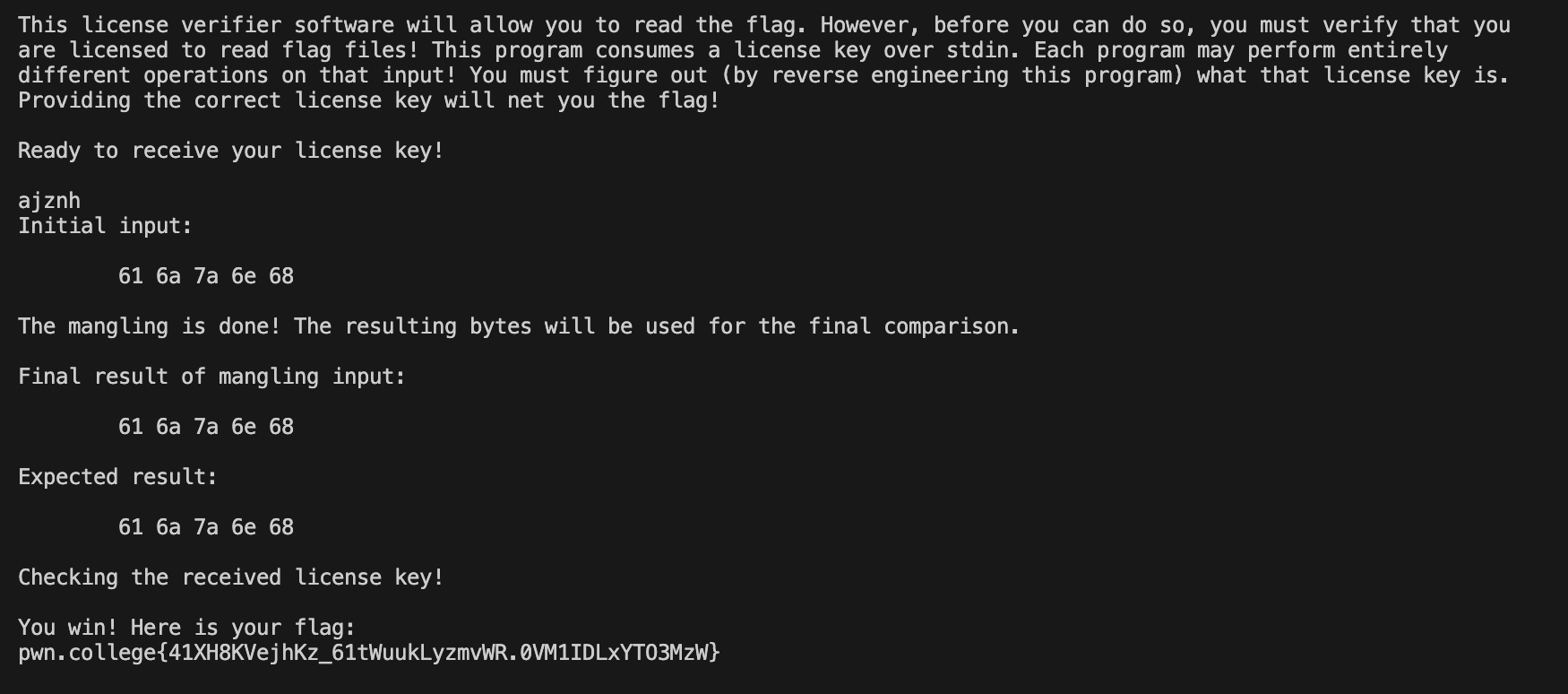
看一下程序
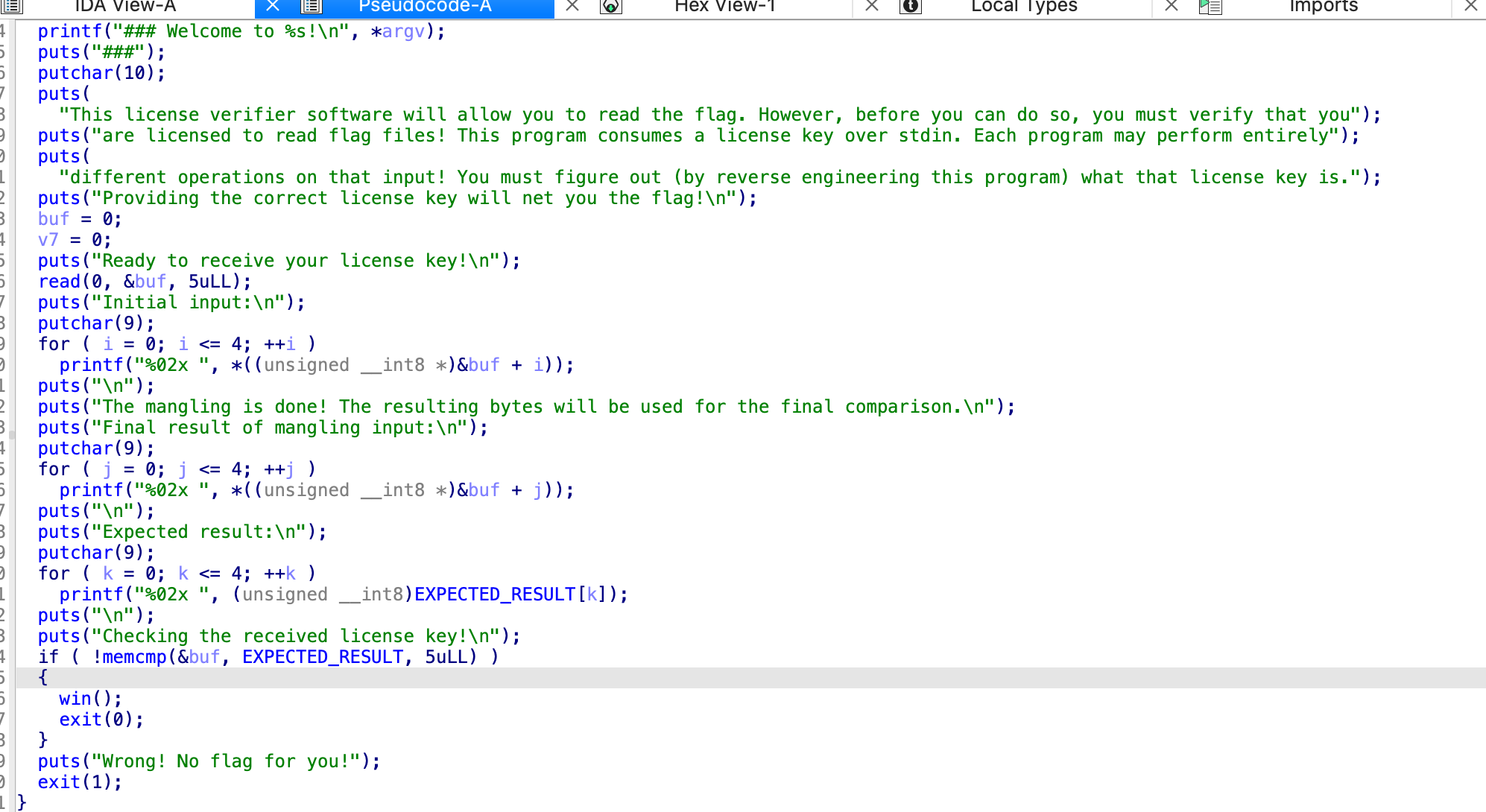
看这个样子,read读入了输出,打印出来对应的ascii码,然后,跟他对应的去比,得到最后的结果,对就给flag,那输入他要的就行
level1.1
没啥区别啊感觉,
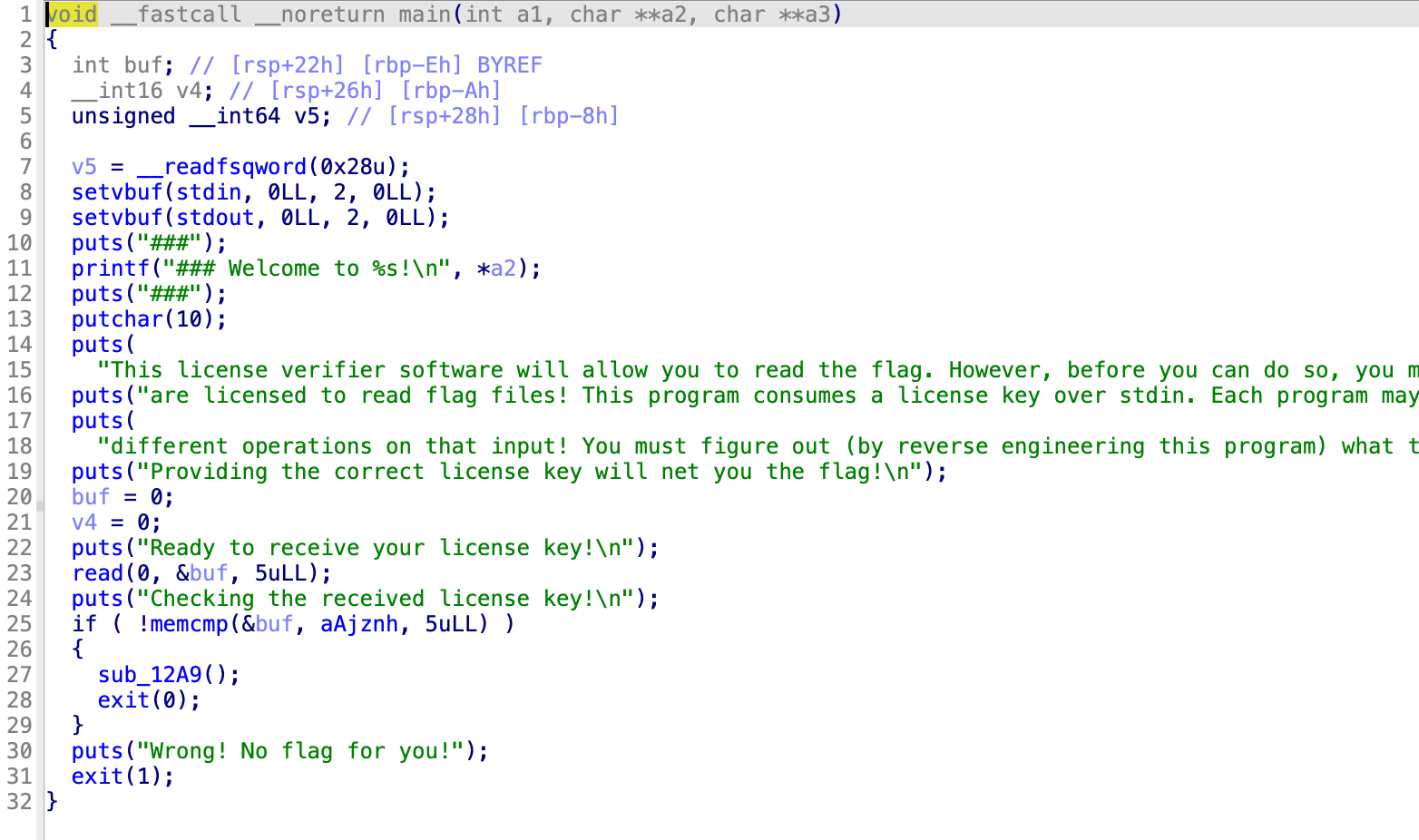
然后那个地址点进去,是数据段的一个数据

Level2.0
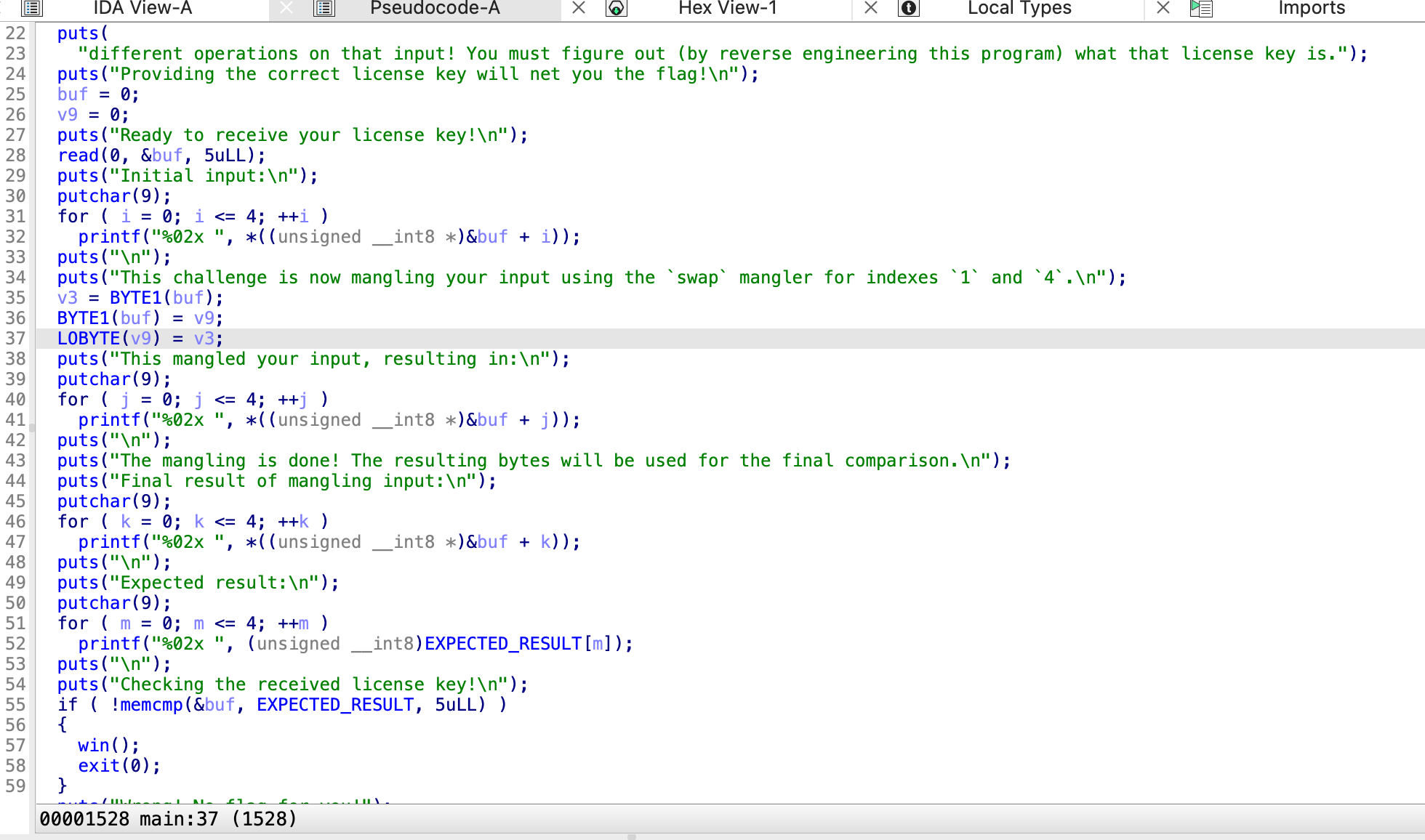
1和4倒换jvsyo
那就是yvsjo,显示不对,那就是josyv
Level2.1
gdkjs
那就是gskjd
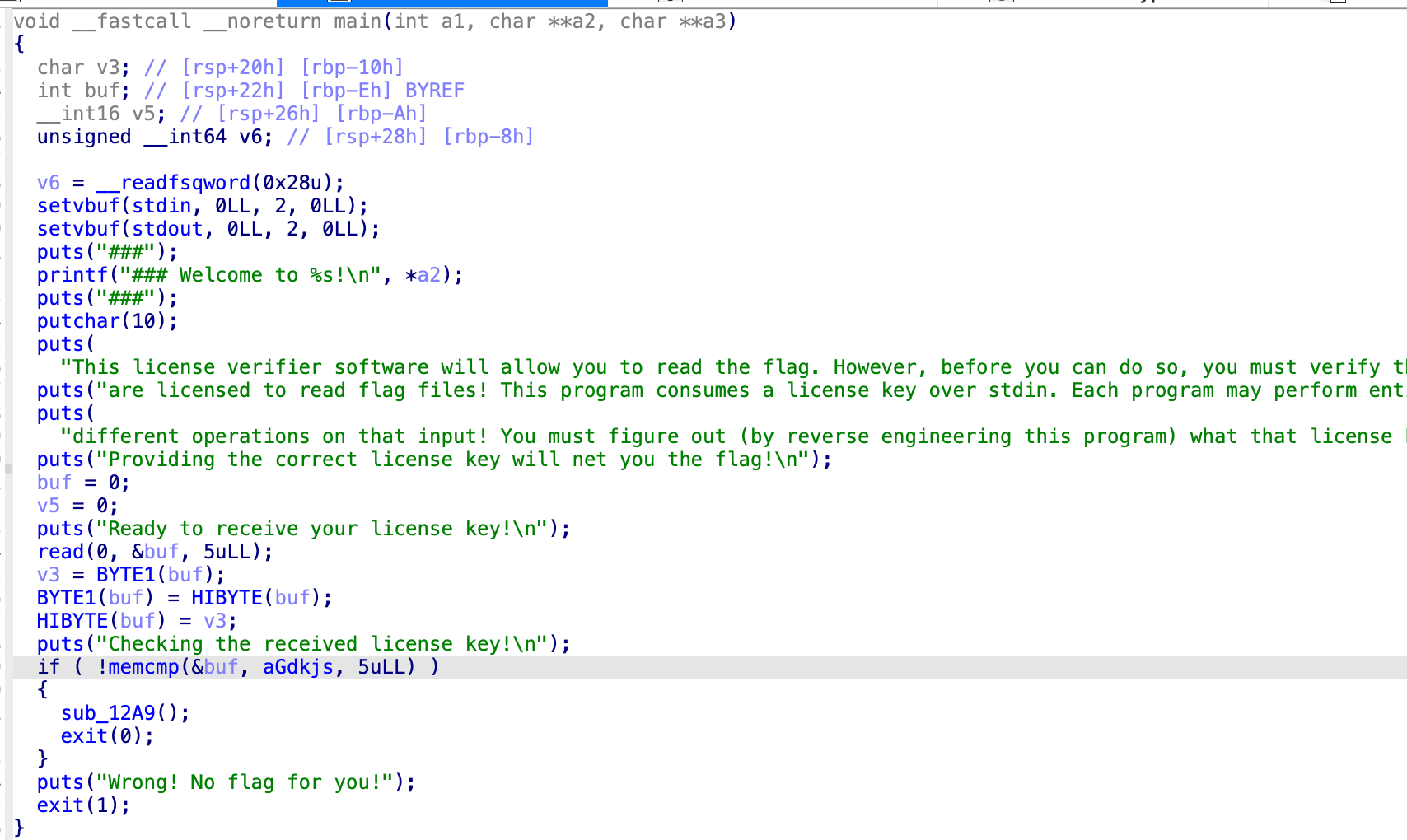
buf是int,4个字节,hibyte很有可能就是第四个字节,因此对应的byte就是第三个,所以
是1和3互换了,gjkds
Level3.0
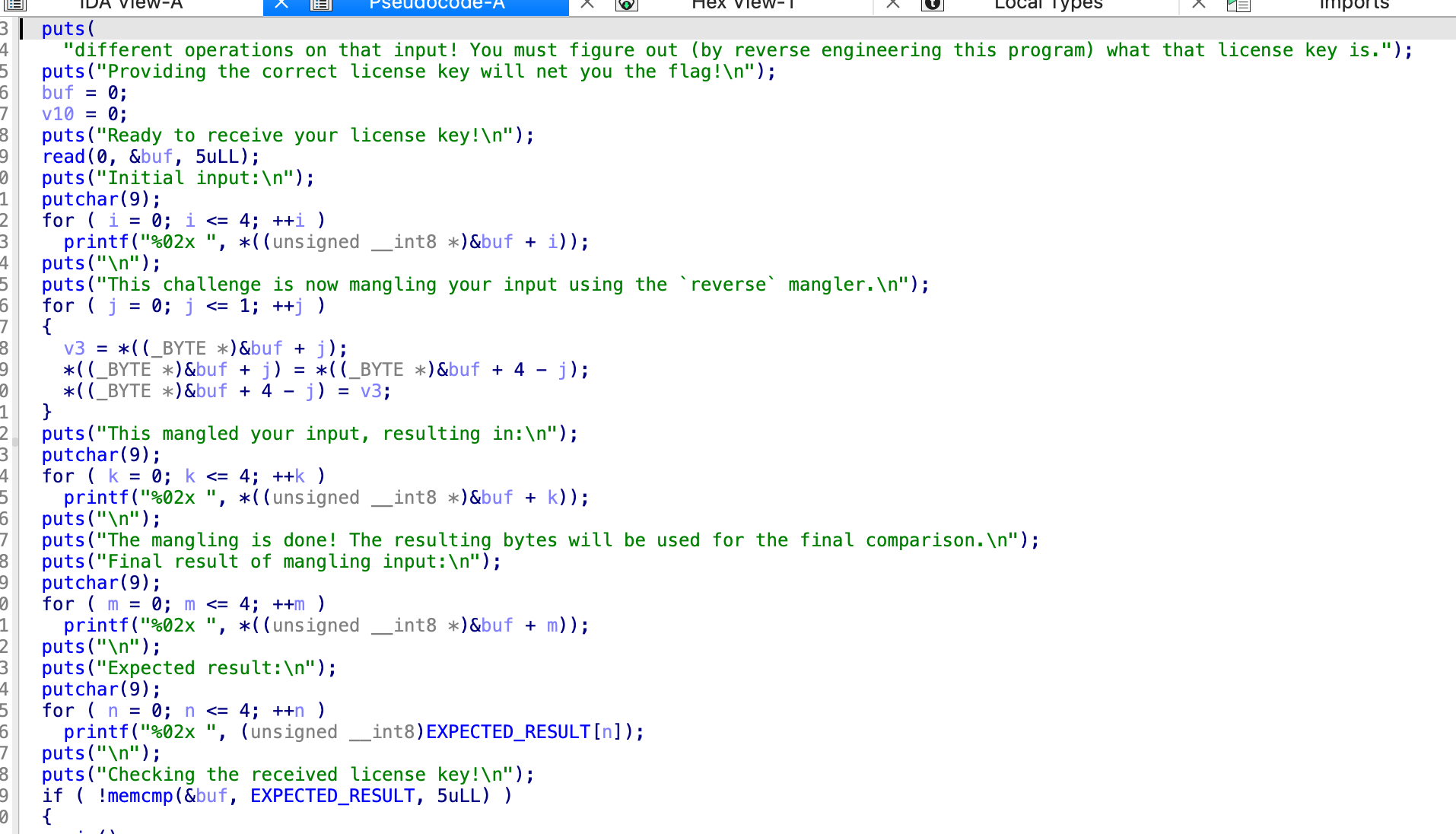
看这个样子,换了两次,第一次0和4互换之后,1和3互换,
hvfsy
ysfvh
level3.1
jcaup
puacj
Level4.0
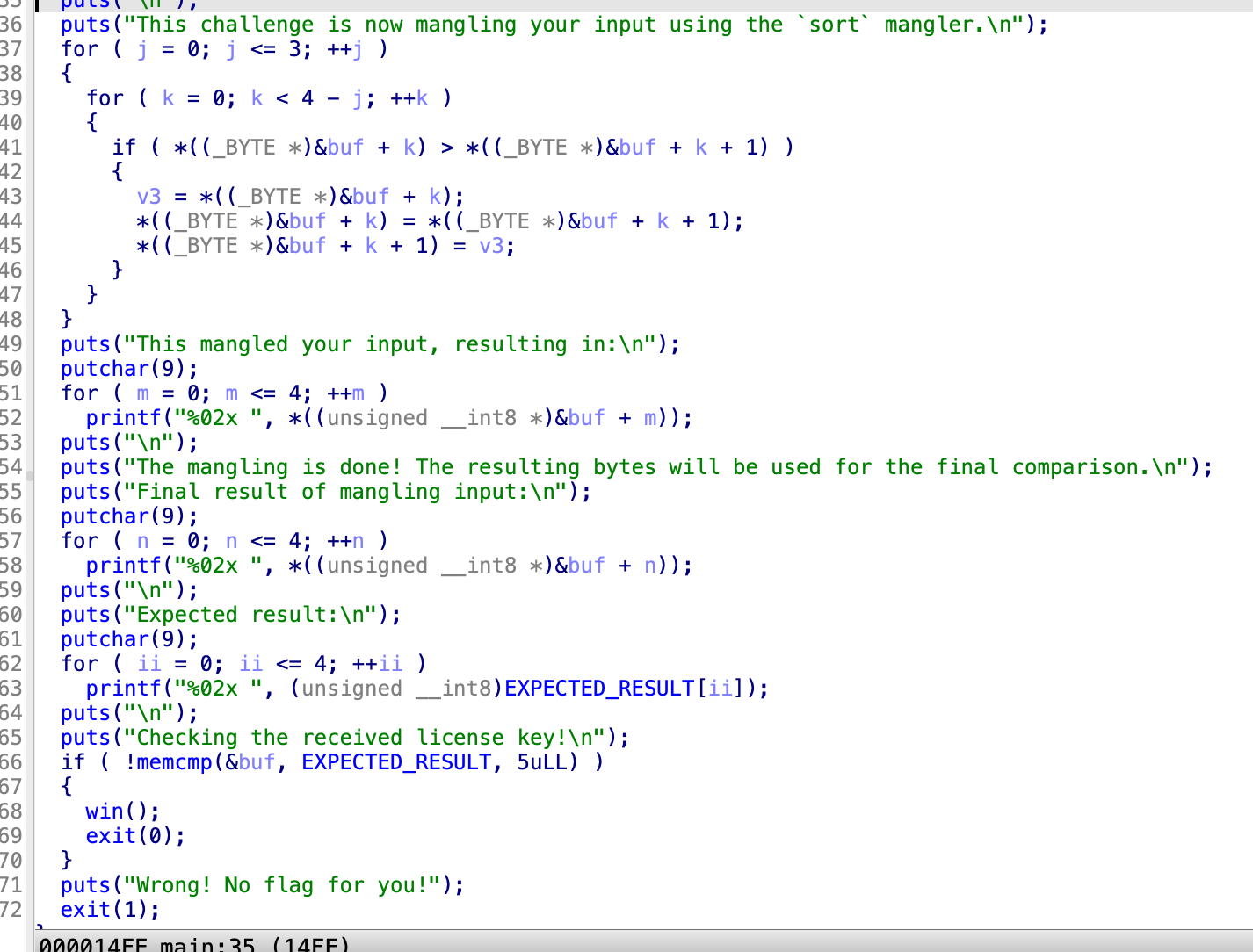
看起来是冒泡
jlvxy
level5.0
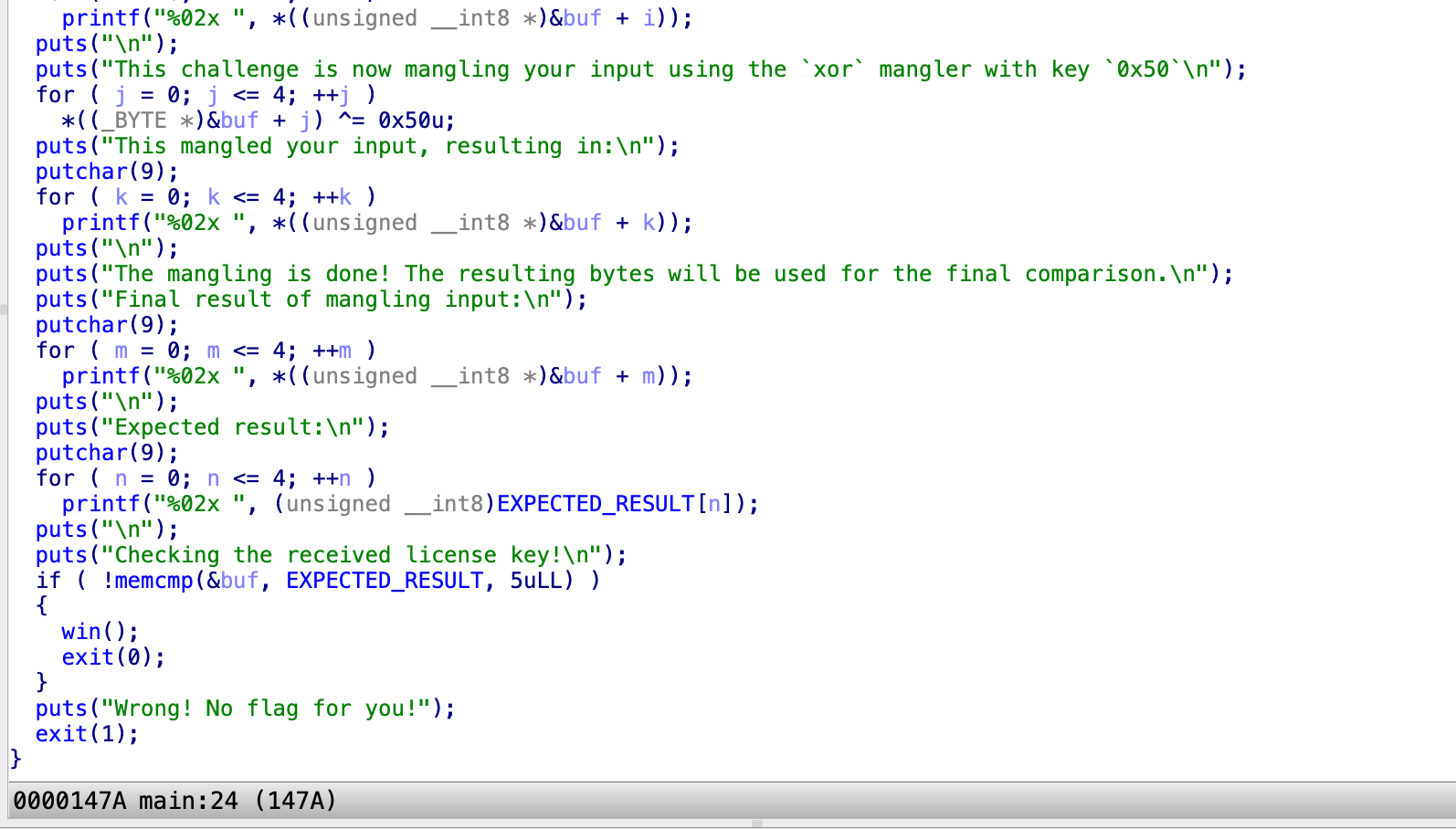
看这个样子是全都异或了0x50,那就他要的再xor一次0x50就抵消了
from pwn import *
def str_to_byte(input_string: str, key: int = 0x50) ->str:
input_bytes = input_string.encode('utf-8')
xor_result = bytes([b ^ key for b in input_bytes])
return xor_result.decode('utf-8', errors='ignore')
str="6?5%("
result=str_to_byte(str,0x50)
print(result)
|
首先encode将其转换为字节,之后异或,然后转换回来
level5.1
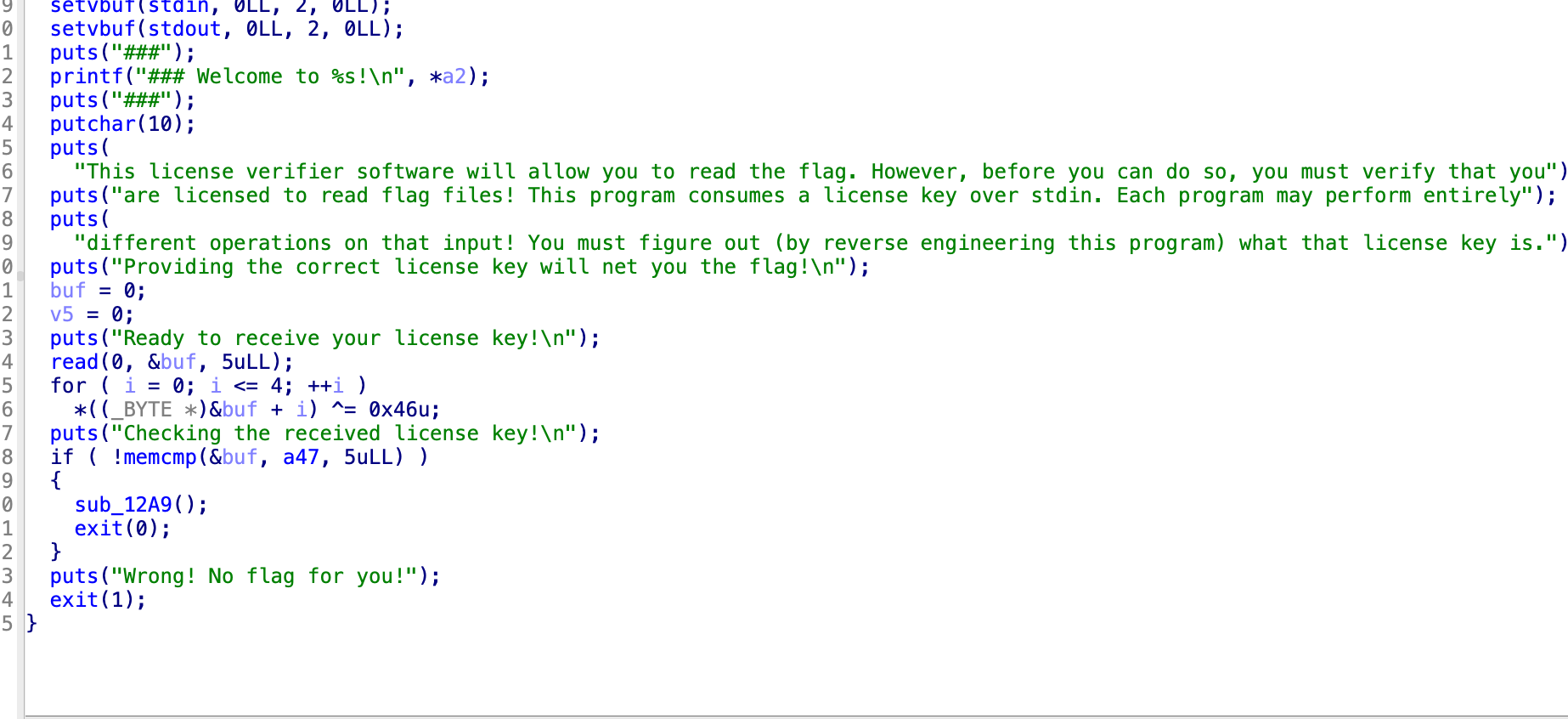
变成了0x46
4</‘,27h,’7
那应该就是4</‘7
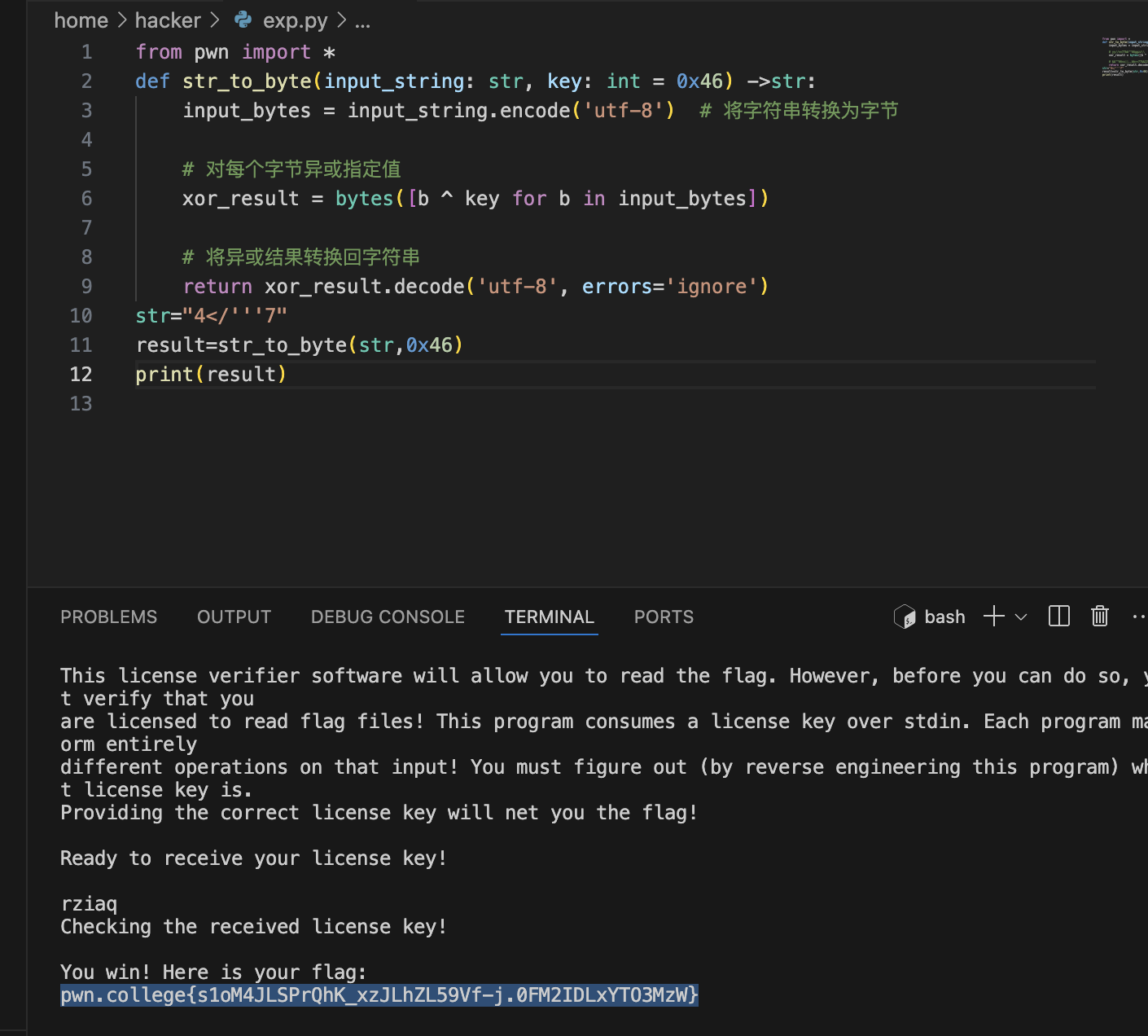
直接在双引号里’,就已经是单引号了
Level6.0
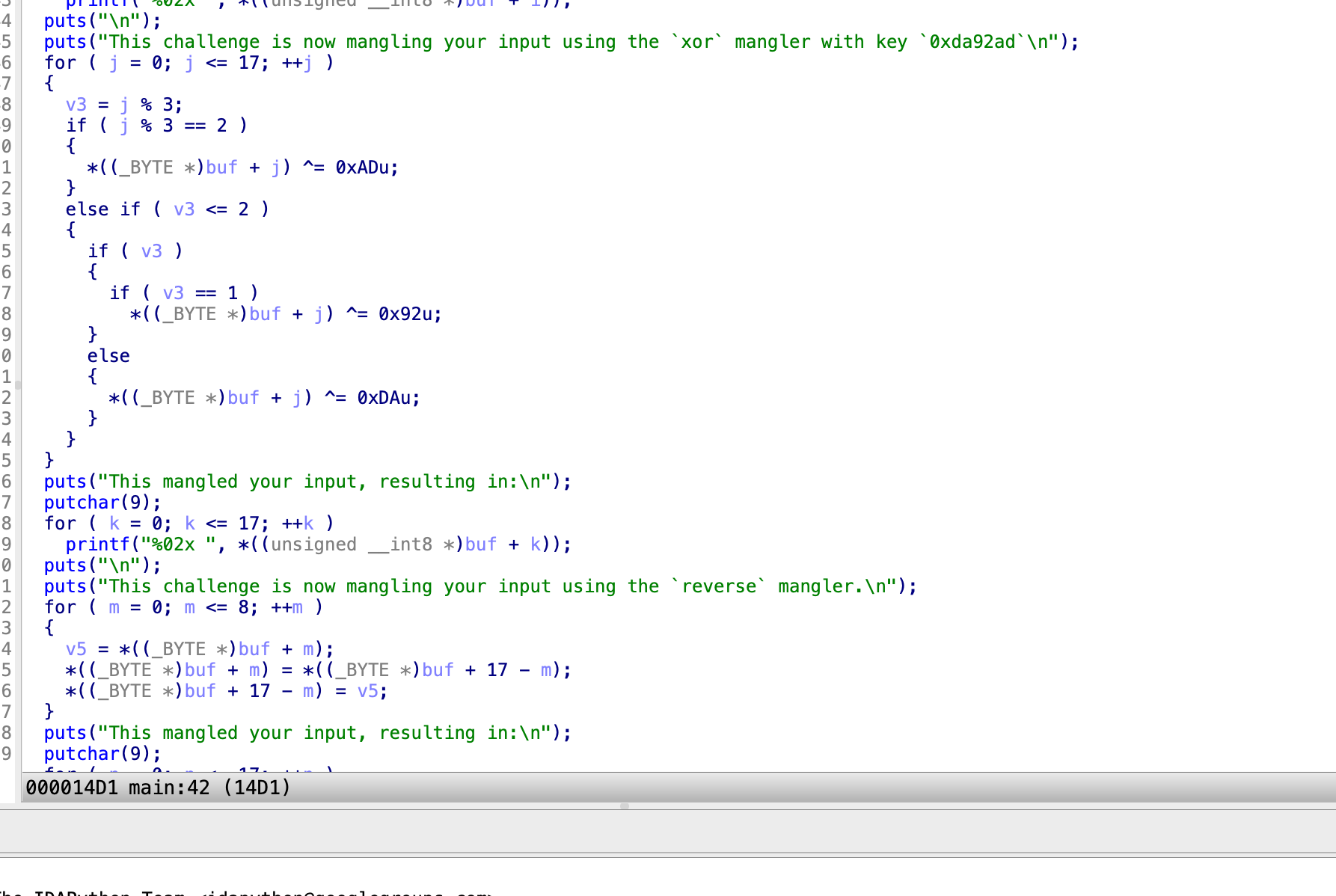
其实就是每三个字节每三个字节的进行异或,并且还进行了逆转,还进行了排序,
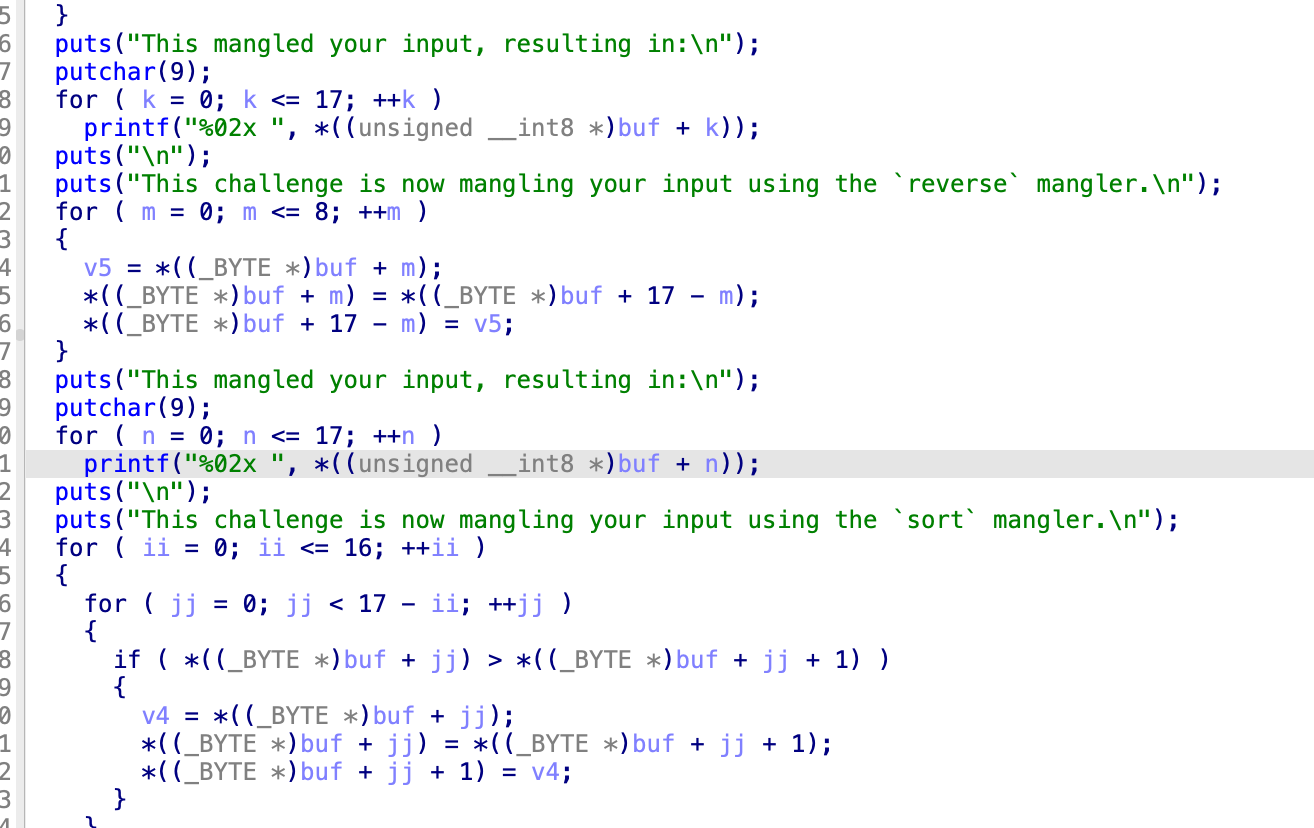
reverse主要把整个字符串反过来,1然后sort进行了一次冒泡排序,所以,对应的expected应该和这个反过来,首先既然是冒泡排序过的,那这个expected本身就应该是一个已经排序过的,果然,
所以只要对应的字节没有错就行,接下来,那这个reverse也没有任何的用哇,但是他每三个字节每三个字节的进行一次对应,如何确保最开始的和最终的那个三字节的对应是一样的呢,所以干脆就不管这些,直接全都逆转一遍,一定是没有错的
果然就是什么都不用管,只需要去对应字节就行,因为排序和那个都是失效的
from pwn import *
def process_hex_list(hex_list):
# 用于存储处理后的字节
processed_bytes = []
# 遍历列表,按每三个字节处理
for i in range(len(hex_list)):
if i % 3 == 0: # 第一个字节
processed_bytes.append(hex_list[i] ^ 0xDA)
elif i % 3 == 1: # 第二个字节
processed_bytes.append(hex_list[i] ^ 0x92)
elif i % 3 == 2: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xAD)
# 转换为字符串
return ''.join(chr(b) for b in processed_bytes)
# 示例十六进制列表
hex_list = [0xA0, 0xAC, 0xB4, 0xB5, 0xB7, 0xB7, 0xC1, 0xC1,
0xC6, 0xCB, 0xD9, 0xDC, 0xE3, 0xE5, 0xE7, 0xE8,
0xEB, 0xFB]
# 调用函数
result = process_hex_list(hex_list)
print(result)
p=process('/challenge/babyrev-level-6-0')
#ques=p.recvuntil(b'Ready to receive your license key!')
#print(ques.decode())
p.sendline(result.encode())
sleep(5) # 等待程序输出完整
out=p.recv(4096)
print(out.decode())
|
最后一个sleep很关键,不然的话调用recv的时候还没有接受完整,同时上面这个对list进行处理之后转换为str的方式可以借鉴,感觉很妙,通过append进行一个个的附加
Level6.1
xqivthjqkczwowzxtdi
0x13个字节,也就是19,
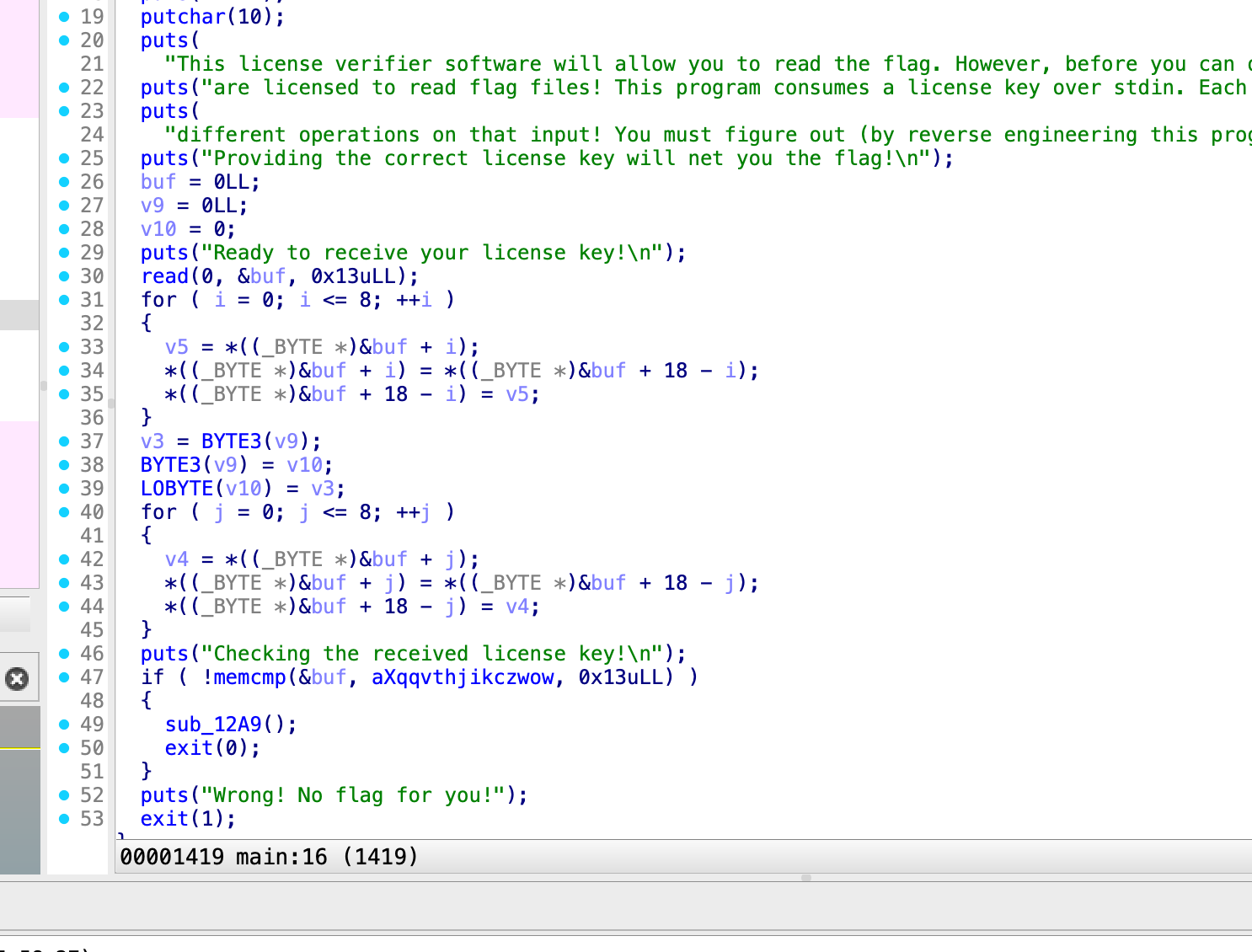
这不就啥也没干没
哦,坑在这里,buf是一个8字节的,而读取了19个字节,因此,后面的v9,v10,一共12个字节里有11个也属于这个范围里,注意中间夹杂里一次,v9的第三个字节,等于第12个字节和v10的最低位,也就是第17个字节进行了对换,所以,因为进行了一次反转,就是第三个和第八个进行了一次互换
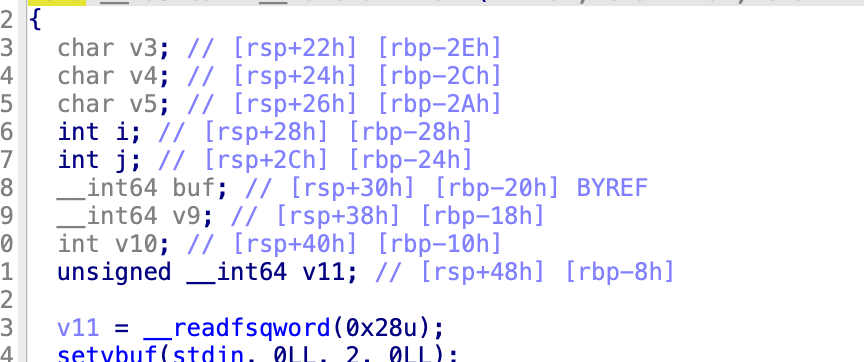
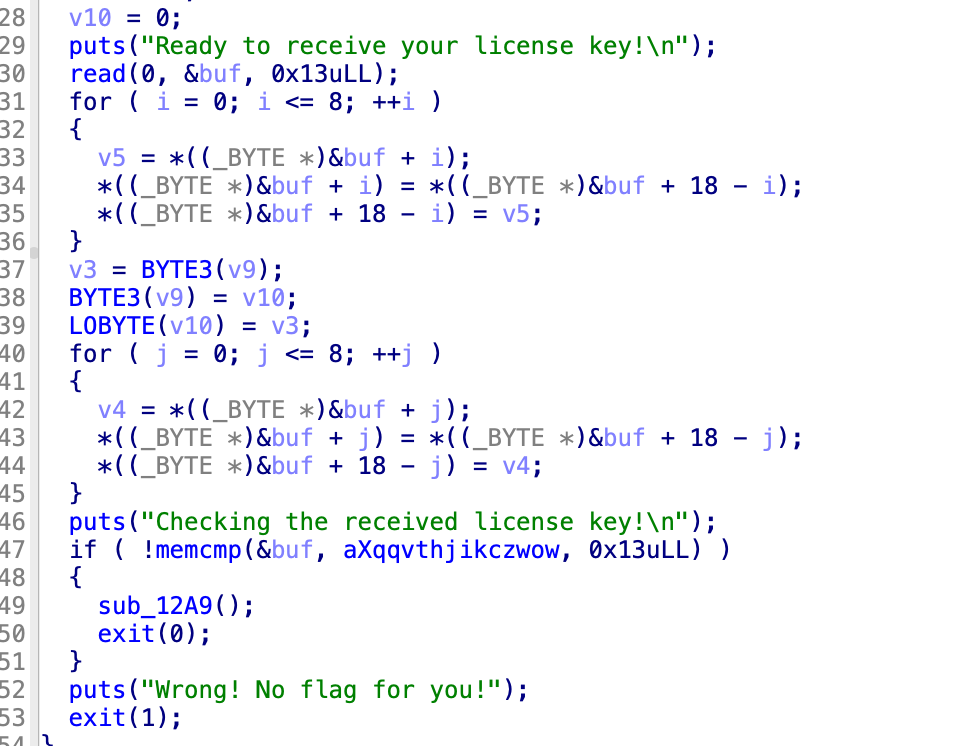
Level7.0
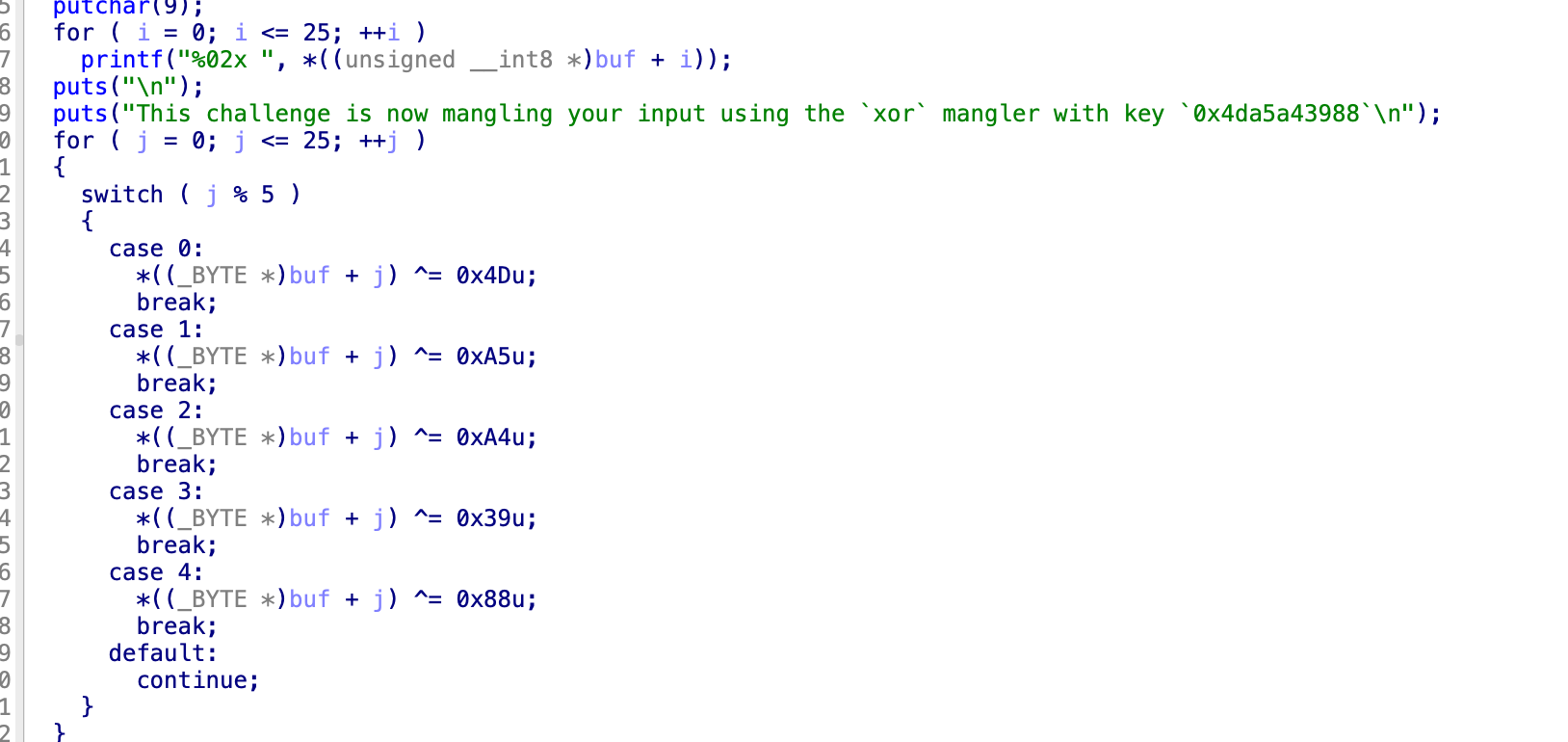
异或变成了以组为单位,其次,输入了26个字符,经过了,异或,逆转,排序,逆转,逆转,那就是说最后实际还是逆转过一次的,把expected,进行一次逆转,之后直接进行异或就是最后的答案,不对,排序在逆转之后,并且之后有两次逆转,所以根本不需要逆转,
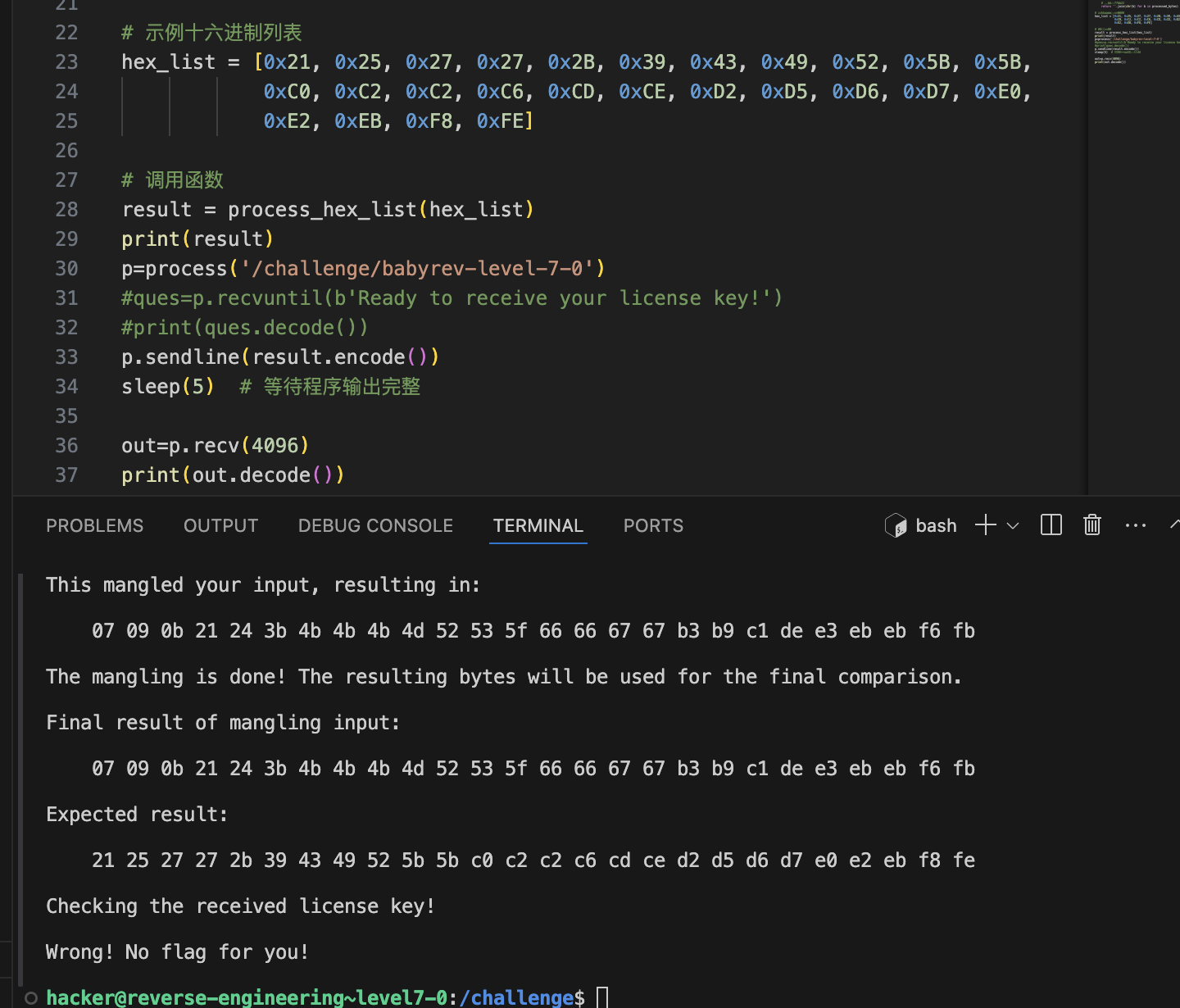
排序是排成一个前小后大的,’a’ \x80
解决了
因为当join的时候,一些不能显示的字符打印成了\x80,这个直接杯join进了字符串,字符串实际已经不能转变为原来的那些raw字节了,发生了变化,因此直接把原始字节传输过去就行了
from pwn import *
def process_hex_list(hex_list):
# 用于存储处理后的字节
processed_bytes = []
# 遍历列表,按每三个字节处理
for i in range(len(hex_list)):
if i % 5 == 0: # 第一个字节
processed_bytes.append(hex_list[i] ^ 0x4d)
print('processed_bytes[%d]: ',i)
print(hex(processed_bytes[i]))
print('\n')
elif i % 5 == 1: # 第二个字节
processed_bytes.append(hex_list[i] ^ 0xa5)
print('processed_bytes[%d]: ',i)
print(hex(processed_bytes[i]))
print('\n')
elif i % 5 == 2: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xa4)
print('processed_bytes[%d]: ',i)
print(hex(processed_bytes[i]))
print('\n')
elif i % 5 == 3: # 第二个节
processed_bytes.append(hex_list[i] ^ 0x39)
print('processed_bytes[%d]: ',i)
print(hex(processed_bytes[i]))
print('\n')
elif i % 5 == 4: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0x88)
print('processed_bytes[%d]: ',i)
print(hex(processed_bytes[i]))
print('\n')
# 转换为字符串
#r1 = ''.join(chr(b) for b in processed_bytes)
#print(r1)
#print(r1.encode('latin1'))
return bytes(processed_bytes)
# 示例十六进制列表
hex_list = [0x21, 0x25, 0x27, 0x27, 0x2B, 0x39, 0x43, 0x49, 0x52, 0x5B, 0x5B,
0xC0, 0xC2, 0xC2, 0xC6, 0xCD, 0xCE, 0xD2, 0xD5, 0xD6, 0xD7, 0xE0,
0xE2, 0xEB, 0xF8, 0xFE]
# 调用函数
result = process_hex_list(hex_list)
print(result)
p=process('/challenge/babyrev-level-7-0')
#ques=p.recvuntil(b'Ready to receive your license key!')
#print(ques.decode())
p.sendline(result)
sleep(5) # 等待程序输出完整
out=p.recv(4096)
print(out.decode())
|
Level7.1


看这个样子,读了0x1c,28个字节,上面存储的时候buf只是一个int64,8个字节,所以,这里v13的第五个字节相当于是第13个字节,然后,v15相当于是第25个字节,这两个进行了互换,之后他们进行了逆序,然后进行了按字节与的操作,之后再次逆序,然后冒泡排序,那么顺序同样还是没有啥用,直接找对应的字节
from pwn import *
def process_hex_list(hex_list):
# 用于存储处理后的字节
processed_bytes = []
# 遍历列表,按每三个字节处理
for i in range(len(hex_list)):
if i % 5 == 0: # 第一个字节
processed_bytes.append(hex_list[i] ^ 0x2c)
print('processed_bytes[%d]: ',i)
print(hex(processed_bytes[i]))
print('\n')
elif i % 5 == 1: # 第二个字节
processed_bytes.append(hex_list[i] ^ 0x1)
print('processed_bytes[%d]: ',i)
print(hex(processed_bytes[i]))
print('\n')
elif i % 5 == 2: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xf3)
print('processed_bytes[%d]: ',i)
print(hex(processed_bytes[i]))
print('\n')
elif i % 5 == 3: # 第二个节
processed_bytes.append(hex_list[i] ^ 0x40)
print('processed_bytes[%d]: ',i)
print(hex(processed_bytes[i]))
print('\n')
elif i % 5 == 4: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xee)
print('processed_bytes[%d]: ',i)
print(hex(processed_bytes[i]))
print('\n')
# 转换为字符串
r1 = ''.join(chr(b) for b in processed_bytes)
print(r1)
print(r1.encode('latin1'))
return bytes(processed_bytes)
# 示例十六进制列表
orign_hex_list = [0x29, 0x2B, 0x2C, 0x30, 0x36, 0x43, 0x48, 0x49, 0x4B, 0x59,
0x5D, 0x60, 0x68, 0x71, 0x72, 0x75, 0x75, 0x81, 0x81, 0x82,
0x83, 0x83, 0x84, 0x87, 0x87, 0x91, 0x97, 0x9B]
orign_hex_list.reverse()
result = process_hex_list(orign_hex_list)
end_hex_list = list(result)
end_hex_list.reverse()
end_hex_list[13], end_hex_list[24] = end_hex_list[24], end_hex_list[13]
end_result = bytes(end_hex_list)
print(result)
p=process('/challenge/babyrev-level-7-1')
#ques=p.recvuntil(b'Ready to receive your license key!')
#print(ques.decode())
p.sendline(end_result)
sleep(5) # 等待程序输出完整
out=p.recv(4096)
print(out.decode())
|
为了避免老眼昏花,直接把他的所有东西都逆转进行了一遍得到结果
Level8.0
读取0x25个字节,也就是37个字节,交换索引为2和30的两个字节,之后进行了排序,之后全都异或0x98,之后进行了倒序,之后,按照三个字节为一组进行异或,然后再逆序,之后6个字节为一组进行异或,当我全都翻过来,到了排序后,那就是一个已经排序完毕的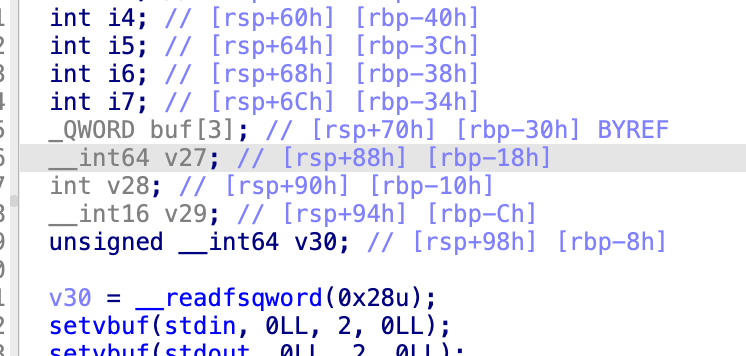
这里的buf是一个24字节的数组




问题出在了
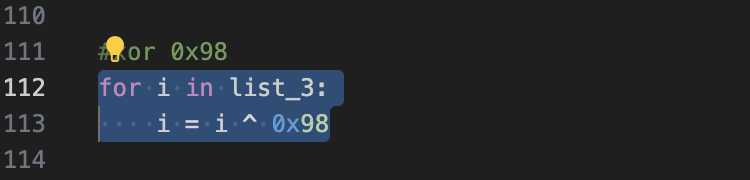
这里没有修改原本的元素,没有解决
from pwn import *
def process_list_6(hex_list):
# 用于存储处理后的字节
processed_bytes = []
# 遍历列表,按每三个字节处理
for i in range(len(hex_list)):
if i % 6 == 0: # 第一个字节
processed_bytes.append(hex_list[i] ^ 0x65)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 6 == 1: # 第二个字节
processed_bytes.append(hex_list[i] ^ 0x5)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 6 == 2: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xdf)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 6 == 3: # 第二个节
processed_bytes.append(hex_list[i] ^ 0x36)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 6 == 4: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0x10)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 6 == 5: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xdf)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
# 转换为字符串
#r1 = ''.join(chr(b) for b in processed_bytes)
#print(r1)
#print(r1.encode('latin1'))
return bytes(processed_bytes)
def process_list_3(hex_list):
# 用于存储处理后的字节
processed_bytes = []
# 遍历列表,按每三个字节处理
for i in range(len(hex_list)):
if i % 3 == 0: # 第一个字节
processed_bytes.append(hex_list[i] ^ 0x86)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 3 == 1: # 第二个字节
processed_bytes.append(hex_list[i] ^ 0x90)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 3 == 2: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0x6f)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
# 转换为字符串
#r1 = ''.join(chr(b) for b in processed_bytes)
#print(r1)
#print(r1.encode('latin1'))
return bytes(processed_bytes)
# 示例十六进制列表
hex_list = [0xF3, 0x79, 0xB5, 0xA2, 0x6A, 0xB3, 0xF7, 0x7D, 0xB0, 0xA6,
0x69, 0xBC, 0xFE, 0x77, 0xBA, 0xAE, 0x7E, 0xA7, 0xE0, 0x68,
0xA4, 0xB2, 0x7A, 0xA2, 0xE7, 0x6E, 0xA1, 0xB7, 0x79, 0xAF,
0xEA, 0x63, 0xAE, 0xB8, 0x74, 0xAD, 0xE8]
#every 6 bytes xor
bytes_6=process_list_6(hex_list)
#transfer to lsit
list_6 = list(bytes_6)
print('-----------this is after xor 6bytes---------------')
print([hex(x) for x in list_6])
#reverse
list_6.reverse()
print('-----------this is after xor reverse---------------')
print([hex(x) for x in list_6])
#every 3 bytes xor
byte_3 = process_list_3(list_6)
#transfer to list
list_3 = list(byte_3)
print('-----------this is after xor 3bytes---------------')
print([hex(x) for x in list_3])
#reverse
list_3.reverse()
print('-----------this is after reverse---------------')
print([hex(x) for x in list_3])
#xor 0x98
xor_value = 0x98
list_xor = [x ^ xor_value for x in list_3]
print('-----------this is after xor 0x98---------------')
print([hex(x) for x in list_xor])
list_xor[2] , list_xor[30] = list_xor[30] , list_xor[2]
end_result = bytes(list_xor)
p=process('/challenge/babyrev-level-8-0')
#ques=p.recvuntil(b'Ready to receive your license key!')
#print(ques.decode())
p.sendline(end_result)
sleep(5) # 等待程序输出完整
out=p.recv(4096)
print(out.decode())
|
问题出在这个反了吗的
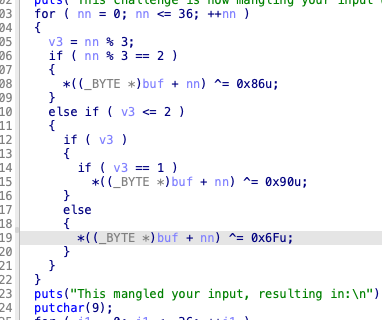
源程序反着来的吗的,解决
Level8.1
观察源程序,read0x25,之后进行逆序,7字节异或,之后第6个字节和第31个字节互换,然后,5字节异或,排序,4字节异或,4字节异或,
from pwn import *
def process_list_7(hex_list):
# 用于存储处理后的字节
processed_bytes = []
# 遍历列表,按每三个字节处理
for i in range(len(hex_list)):
if i % 7 == 0: # 第一个字节
processed_bytes.append(hex_list[i] ^ 0x8f)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 7 == 1: # 第二个字节
processed_bytes.append(hex_list[i] ^ 0x7)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 7 == 2: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0x6e)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 7 == 3: # 第二个节
processed_bytes.append(hex_list[i] ^ 0xa2)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 7 == 4: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xf8)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 7 == 5: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xb6)
elif i % 7 == 6: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xbc)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
# 转换为字符串
#r1 = ''.join(chr(b) for b in processed_bytes)
#print(r1)
#print(r1.encode('latin1'))
return bytes(processed_bytes)
def process_list_5(hex_list):
# 用于存储处理后的字节
processed_bytes = []
# 遍历列表,按每三个字节处理
for i in range(len(hex_list)):
if i % 5 == 0: # 第一个字节
processed_bytes.append(hex_list[i] ^ 0x3d)
elif i % 5 == 1: # 第二个字节
processed_bytes.append(hex_list[i] ^ 0x77)
elif i % 5 == 2: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xc1)
elif i % 5 == 3: # 第二个节
processed_bytes.append(hex_list[i] ^ 0x64)
elif i % 5 == 4: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0x66)
return bytes(processed_bytes)
def process_list_4_1(hex_list):
# 用于存储处理后的字节
processed_bytes = []
# 遍历列表,按每三个字节处理
for i in range(len(hex_list)):
if i % 4 == 0: # 第一个字节
processed_bytes.append(hex_list[i] ^ 0x49)
elif i % 4 == 1: # 第二个字节
processed_bytes.append(hex_list[i] ^ 0x4e)
elif i % 4 == 2: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0x47)
elif i % 4 == 3: # 第二个节
processed_bytes.append(hex_list[i] ^ 0x78)
return bytes(processed_bytes)
def process_list_4_2(hex_list):
# 用于存储处理后的字节
processed_bytes = []
# 遍历列表,按每三个字节处理
for i in range(len(hex_list)):
if i % 4 == 0: # 第一个字节
processed_bytes.append(hex_list[i] ^ 0x93)
elif i % 4 == 1: # 第二个字节
processed_bytes.append(hex_list[i] ^ 0xcd)
elif i % 4 == 2: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0xcd)
elif i % 4 == 3: # 第二个节
processed_bytes.append(hex_list[i] ^ 0x39)
return bytes(processed_bytes)
def process_list_3(hex_list):
# 用于存储处理后的字节
processed_bytes = []
# 遍历列表,按每三个字节处理
for i in range(len(hex_list)):
if i % 3 == 0: # 第一个字节
processed_bytes.append(hex_list[i] ^ 0x6f)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 3 == 1: # 第二个字节
processed_bytes.append(hex_list[i] ^ 0x90)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
elif i % 3 == 2: # 第三个字节
processed_bytes.append(hex_list[i] ^ 0x86)
# print('processed_bytes[%d]: ',i)
# print(hex(processed_bytes[i]))
# print('\n')
# 转换为字符串
#r1 = ''.join(chr(b) for b in processed_bytes)
#print(r1)
#print(r1.encode('latin1'))
return bytes(processed_bytes)
# 示例十六进制列表
hex_list = [0xDA, 0x80, 0x8E, 0x45, 0xCB, 0x97, 0x93, 0x65, 0xF3, 0xD0,
0xDC, 0x21, 0xB8, 0xED, 0x1B, 0xD9, 0x44, 0x21, 0x22, 0xE9,
0x70, 0x2F, 0x38, 0xF3, 0x68, 0x36, 0x3D, 0xF8, 0x19, 0x5B,
0x56, 0xA5, 0x36, 0x70, 0x7C, 0xBA, 0x21]
#every 4_2 bytes xor
bytes_4_2=process_list_4_2(hex_list)
#transfer to lsit
list_4_2 = list(bytes_4_2)
#every 4_1 bytes xor
bytes_4_1=process_list_4_1(list_4_2)
#transfer to lsit
list_4_1 = list(bytes_4_1)
#every 5 bytes xor
bytes_5=process_list_5(list_4_1)
#transfer to lsit
list_5 = list(bytes_5)
#swap
list_5[5] , list_5[30] = list_5[30] , list_5[5]
#every 5 bytes xor
bytes_7=process_list_7(list_5)
#transfer to lsit
list_7 = list(bytes_7)
list_7.reverse()
end_result = bytes(list_7)
p=process('/challenge/babyrev-level-8-1')
#ques=p.recvuntil(b'Ready to receive your license key!')
#print(ques.decode())
p.sendline(end_result)
sleep(2) # 等待程序输出完整
out=p.recv(4096)
print(out.decode())
|
Level9.0
这题没太看懂,先看看让干啥吧
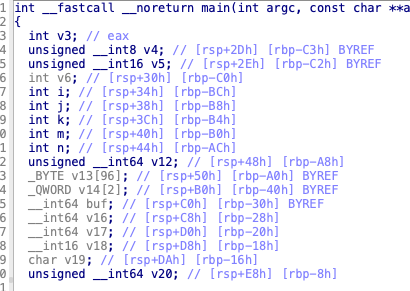
首先看这个,他read0x1a,也就是26个字节,但是buf只有8字节,buf,v16,v17和v18的低2字节都在read里,
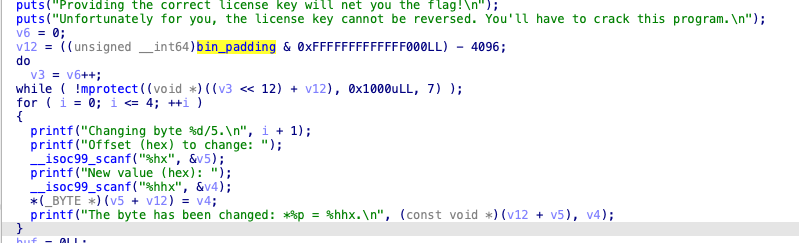
看挑战程序的话,就是
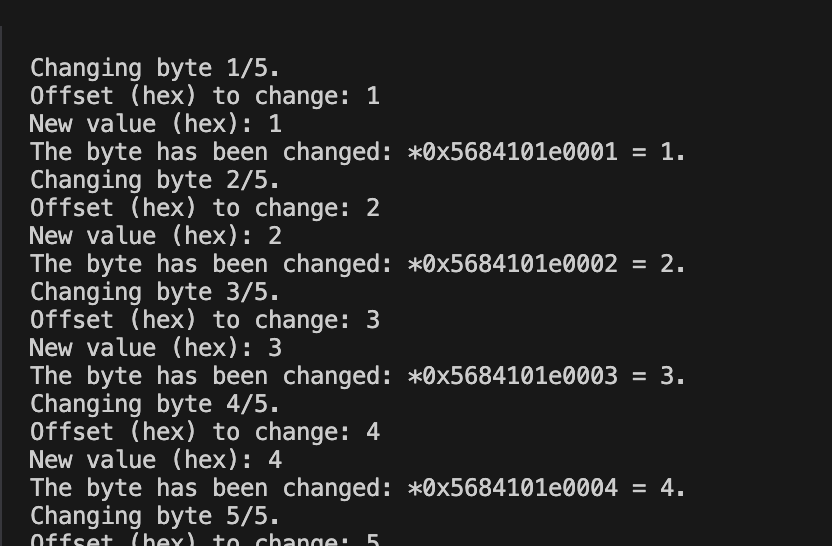
更改了这几个位置的字节,那就是v5是填写的偏移,v4是填写的目标字节的值,v5是16位的数,之后,读取了之后,他通过md5进行了哈希,因此不可逆,之后,帖子说这个v12是程序加载基址,那么,原来如此,这里可以任意patch,所以说,可以直接将最后win的那个判断改成不相等才跳过,那这样的话就直接win了
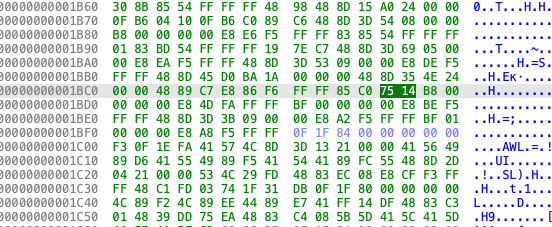
jnz是0x75,而jz是0x74,他是
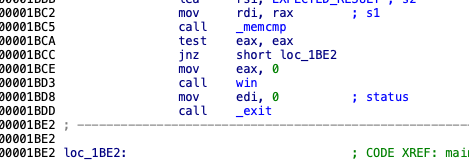
在不等于这里,他是不等于才跳走,所以改成等于条件不成立就不跳走了
Level9.1
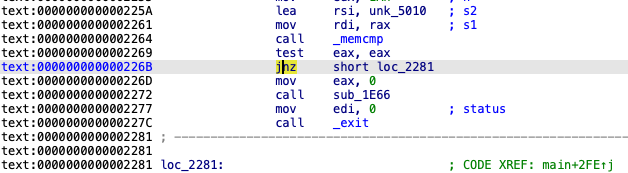
226b处
Level10.0
只允许一个字节了,
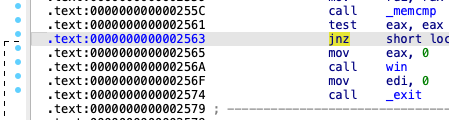
level10.1
0x23c1
level11.0

说是之后会检查,然后让修改两次,所以我才回头还要修改回来
是对s1和s2的内容进行了一个相同性检查,所以,正常的修改,触发了完整性检查,为什么呢, 懂了,还需要把那个检查完整性的改了,

222b
拿下
Level11.1
2559,247b,这里有一个坑,就是他是一个拓展过的jnz,是0f 85,后面跟着32位的偏移量,而之前的是跟着8位的,所以这里应该是247c,变成0x84
Level12.0
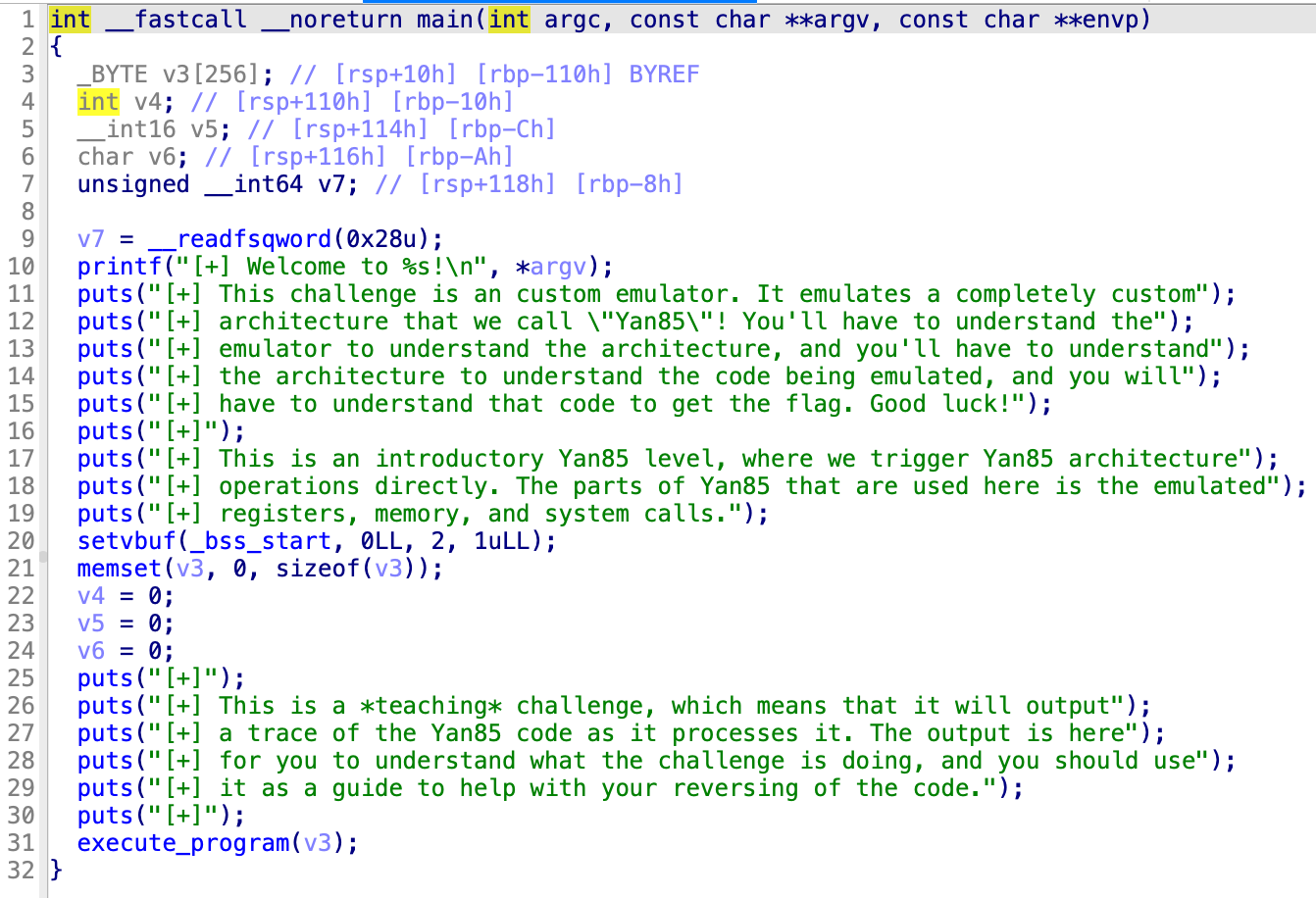
主程序没有看到什么特殊的,之后运转了下面那个函数,传入了v3,也就是256个字节的0,
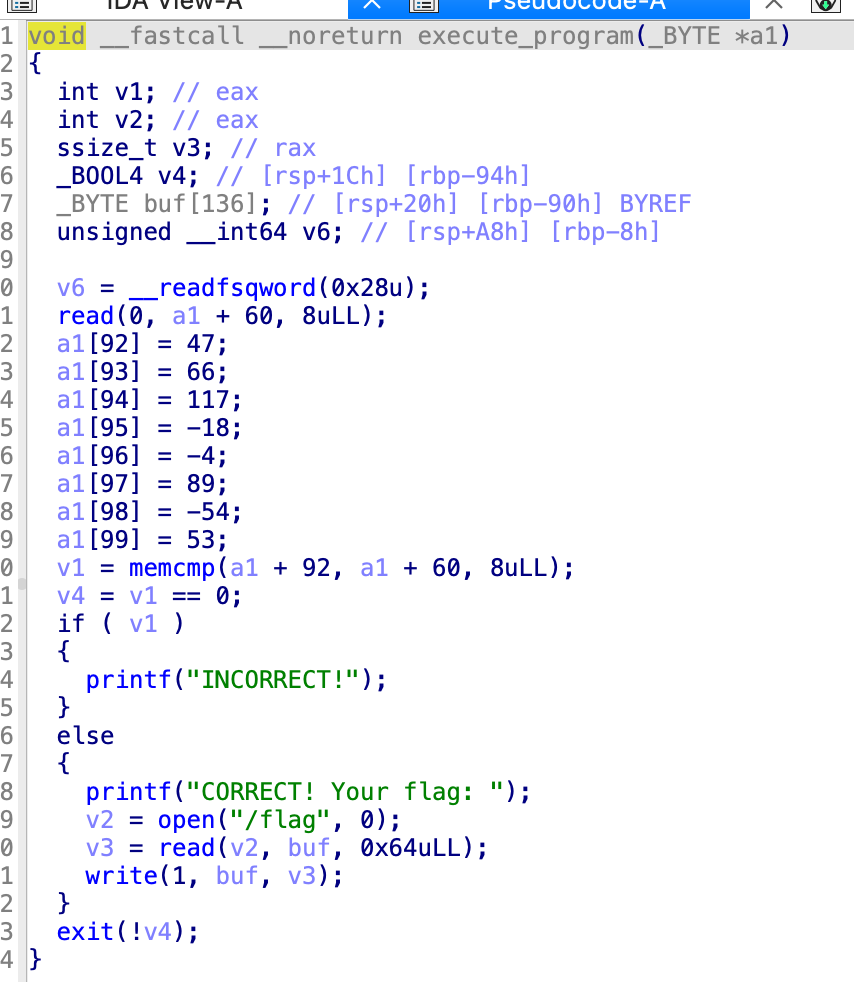
在这个函数里面,首先读入了8个字节,放在了a1[60]的位置,然后,赋值了一系列的,从a1[92]到a1[99]的8个字节,之后v1被赋值为memcmp的返回值,比较的就是这两个8字节,如果v1是非0,那不对,如果说v1为0才会打印,那就是要这两个位置都相同呗,
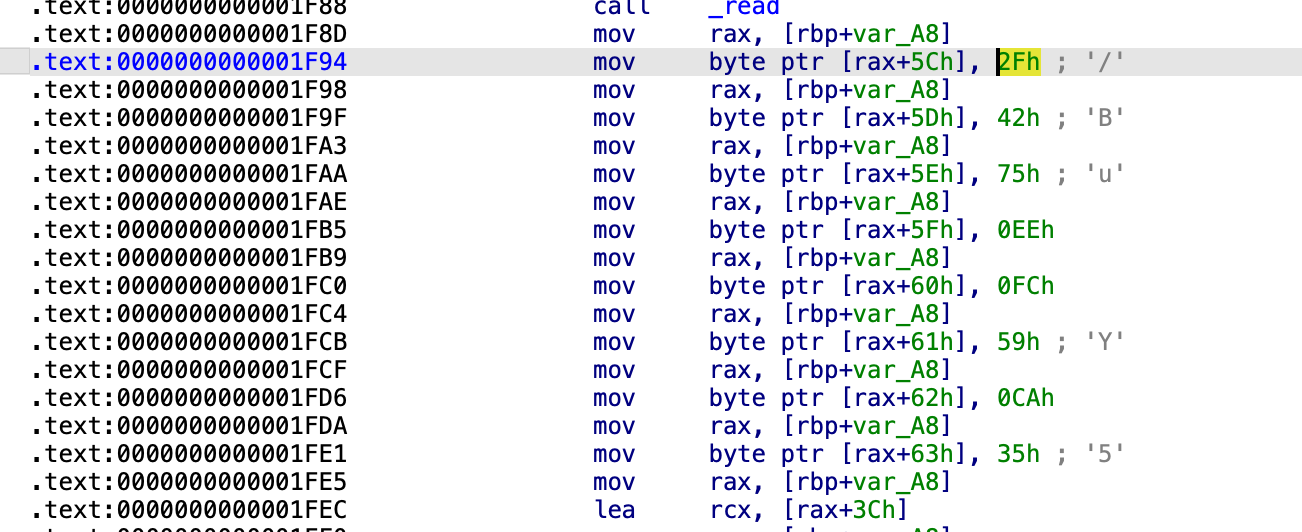
要发的字节就是这些了,那么发送的方式有很多种,第一种是通过struct中的pack函数将数字转换为二进制数据并且按照指定格式打包
a1 = [47, 66, 117, -18, -4, 89, -54, 53]
data = struct.pack('8b', *a1)
|
第二种是通过array模块的array创建一个字节数组
# 要发送的数值
a1 = [47, 66, 117, -18, -4, 89, -54, 53]
# 使用 array 模块创建一个包含字节的数组
# 'b' 表示有符号字节(signed char)
byte_array = array.array('b', a1)
# 发送字节数据
p.send(byte_array.tobytes())
|
第三个是通过手动转换,因为一个字节的话,负数用的是他的补码形式
a1 = [47, 66, 117, -18, -4, 89, -54, 53]
data = bytearray(((x + 256) % 256) for x in a1)
|
注意,bytes和b’’不一样,bytes是一个内建类型,表示不可变的字节序列,而b‘’是通过在字符串前面添加b表示这是一个字节序列
from pwn import *
p=process('/challenge/babyrev-level-12-0')
a1 = [47, 66, 117, -18, -4, 89, -54, 53]
# 将每个数值转换为字节,并打包成二进制数据
# 使用 'b' 格式符,表示一个字节(signed char),范围是 -128 到 127
# 如果需要处理负数,struct 会将其转换为 2 的补码表示
data = bytes([((x + 256) % 256) for x in a1])
或者
data = bytes([0x2f,0x42,0x75,0xee,0xfc,0x59,0xca,0x35])
p.send(data)
sleep(2) # 等待程序输出完整
out=p.recv(4096)
print(out.decode())
|
Level12.1
Level13.0
让我们深入研究逆向工程混淆代码!此挑战使用基于 VM 的混淆:逆向工程自定义模拟器和架构以了解如何获取标志!如果你很聪明的话,你就不需要逆向太多的 VM 代码。
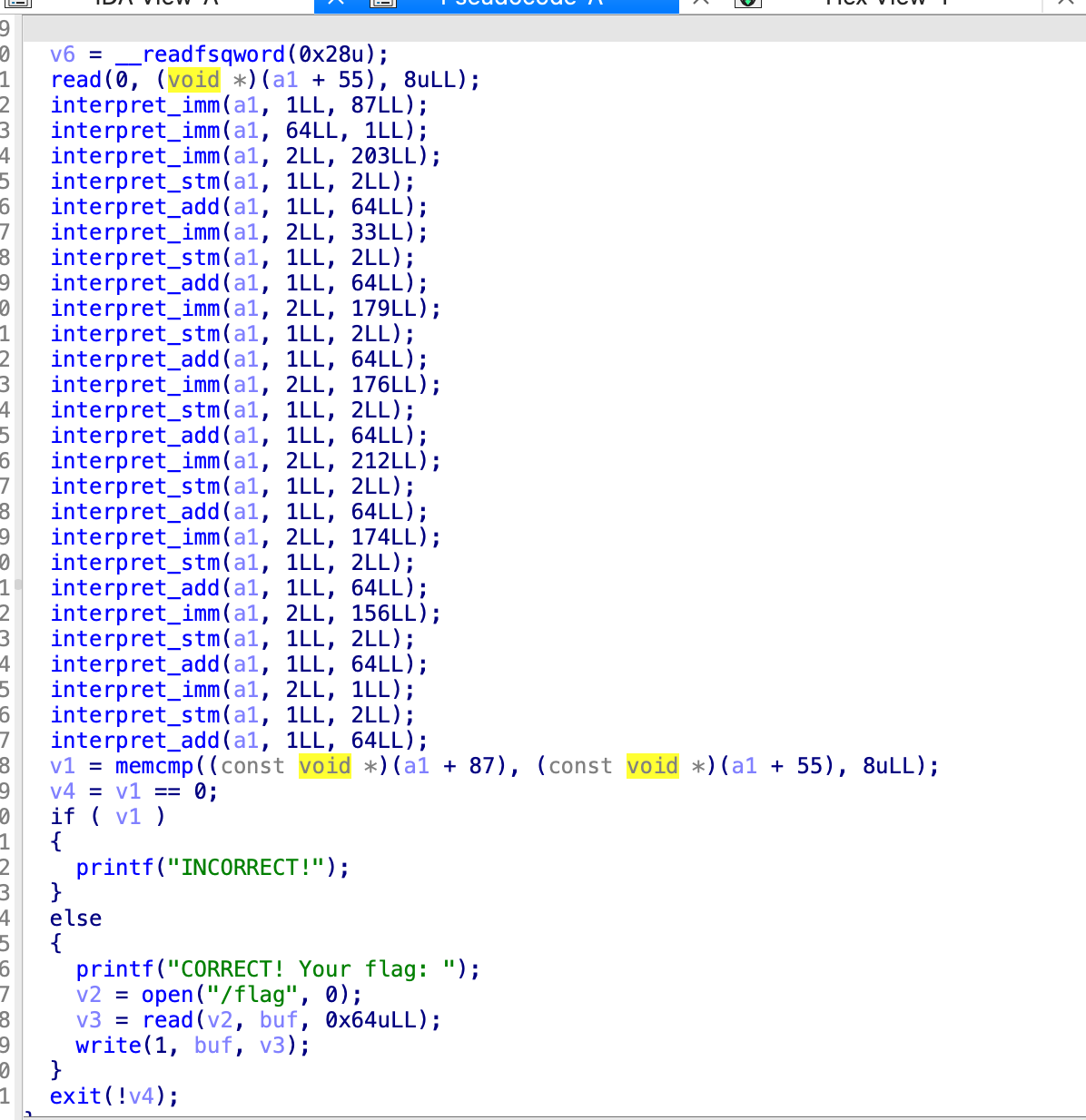
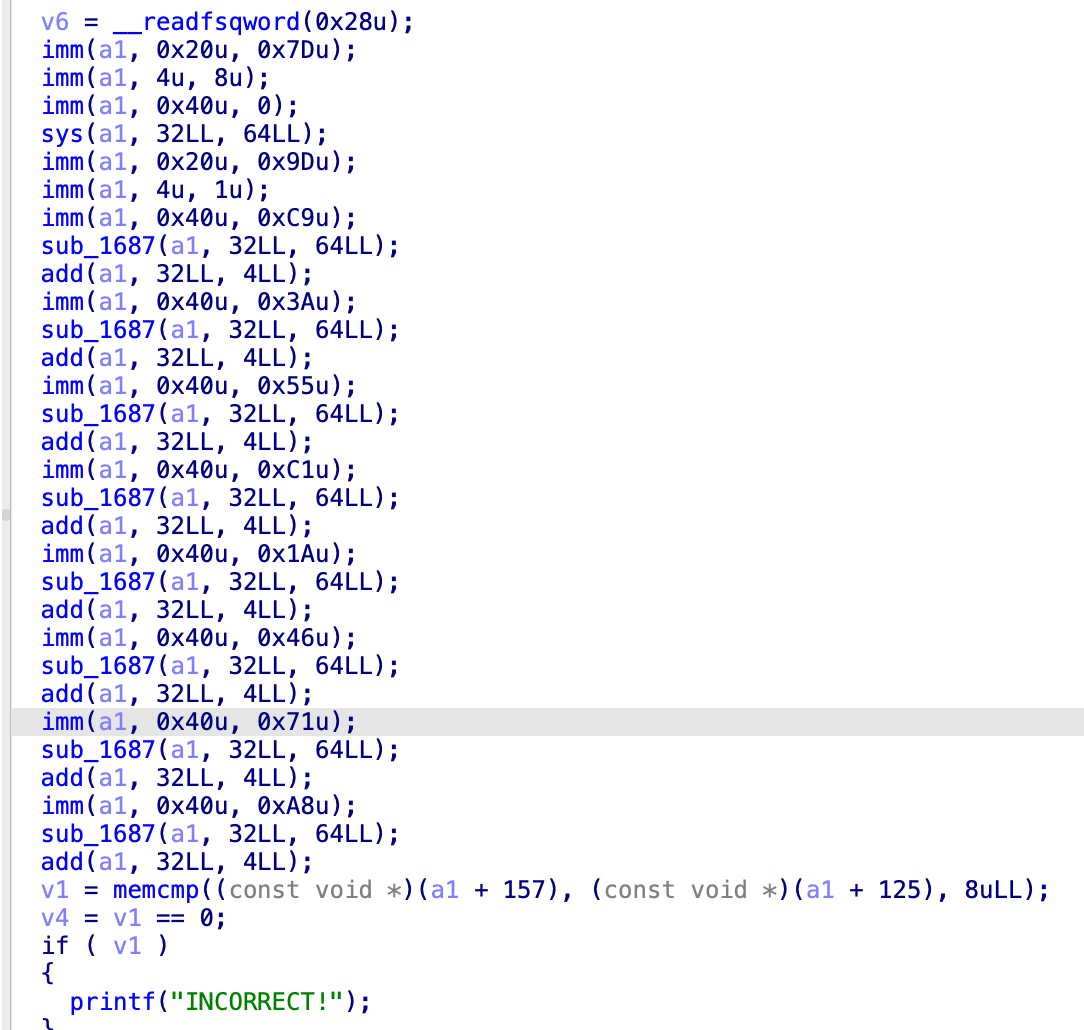
这里来看,他读取了8个字节到a1+55这个位置,之后
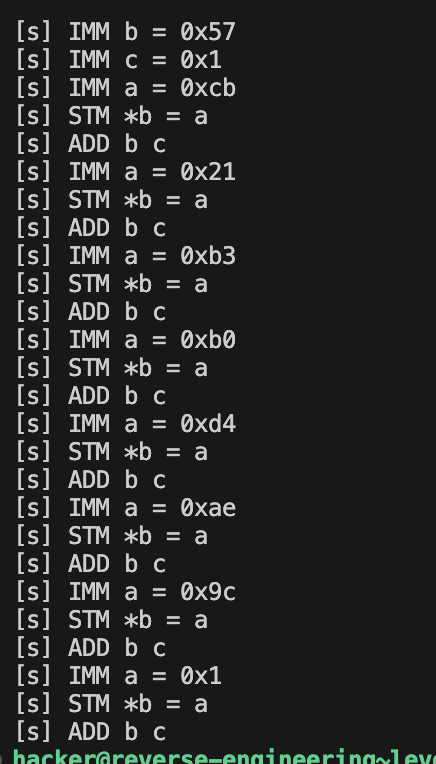
目的仍然是a1+87的8个字节和a1+55的8个字节相同,这个函数传进来了一个256字节的起始位置,
三个参数,第二个参数来看,1是b,64是c,2是a,
首先看看这个样子,stm *0x87就是0xcb,stm *0x88为0x21,也就是说以b为基底,然后c为一个1,每次加一下他,那8个字节就是,0xcb,0x21,0xb3,0xb0,0xd4,0xae,0x9c,0x1
Level13.1
这8个字节应该说,

传入的仍然是256个字节的0,之后,
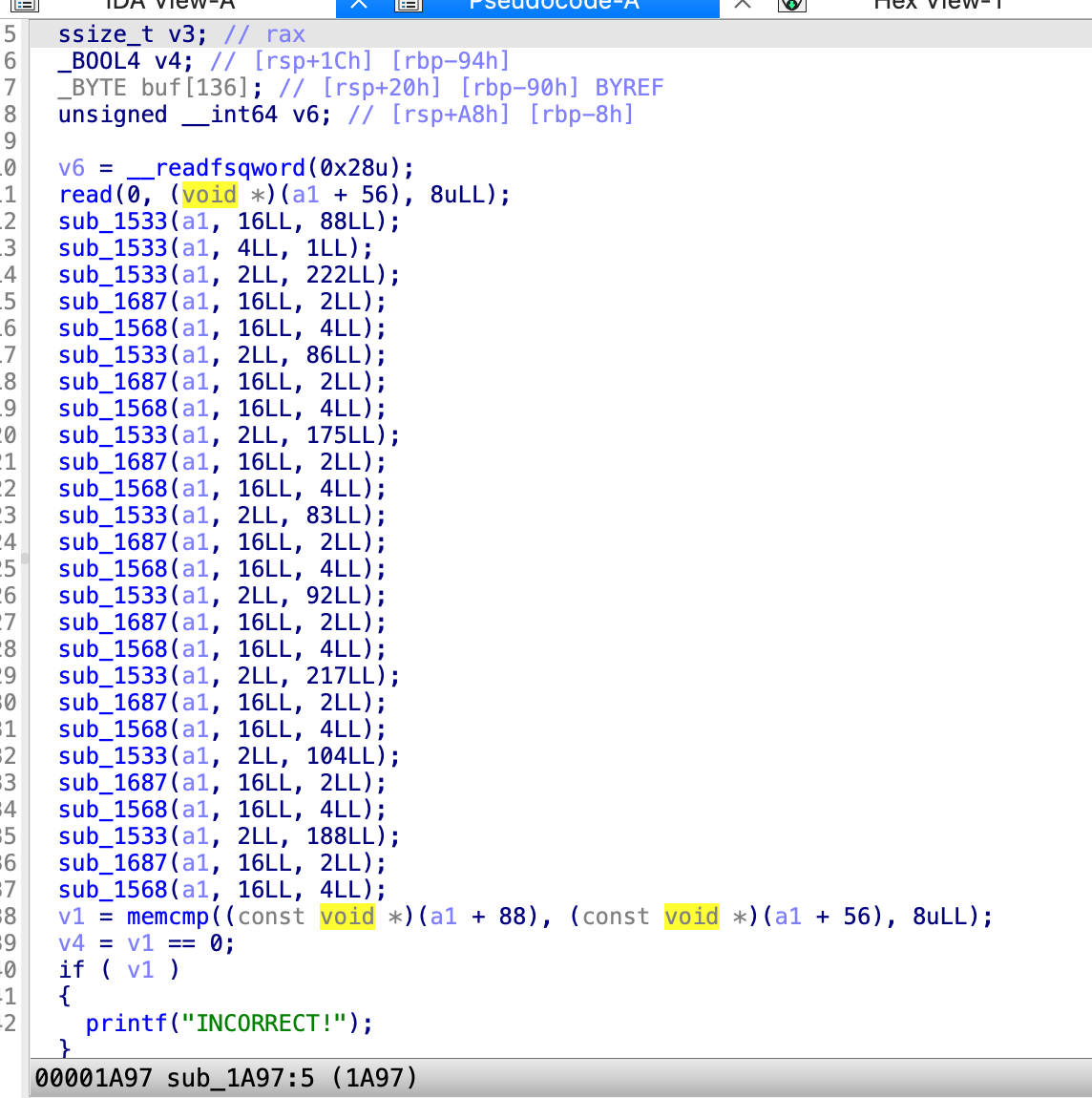
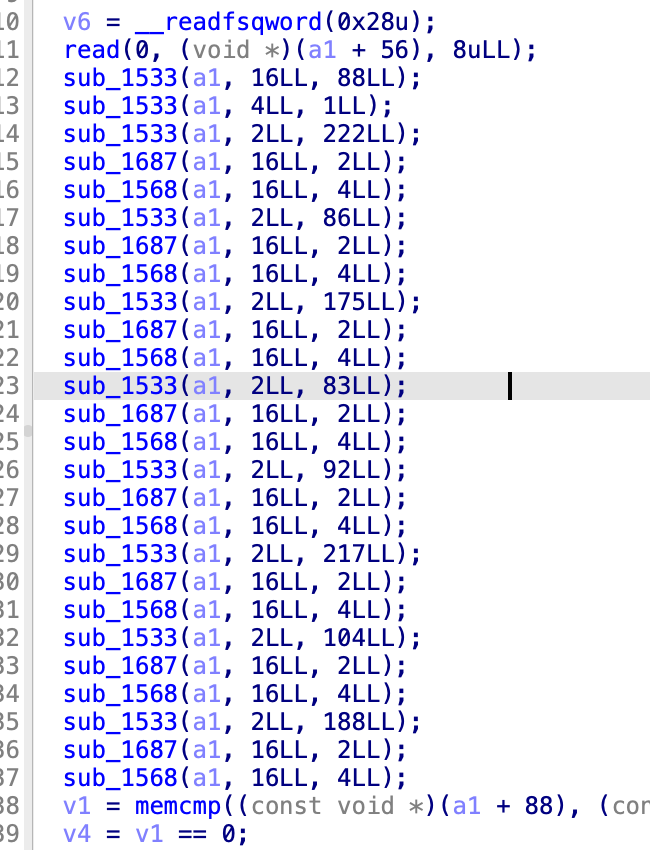
sub1533又跳到了sub1415,然后这里是,a3为位置,a2是对应的变量代表的值
那也就是说16这等于88,然后4等于1,这一个应该是那个索引,之后2等于222,
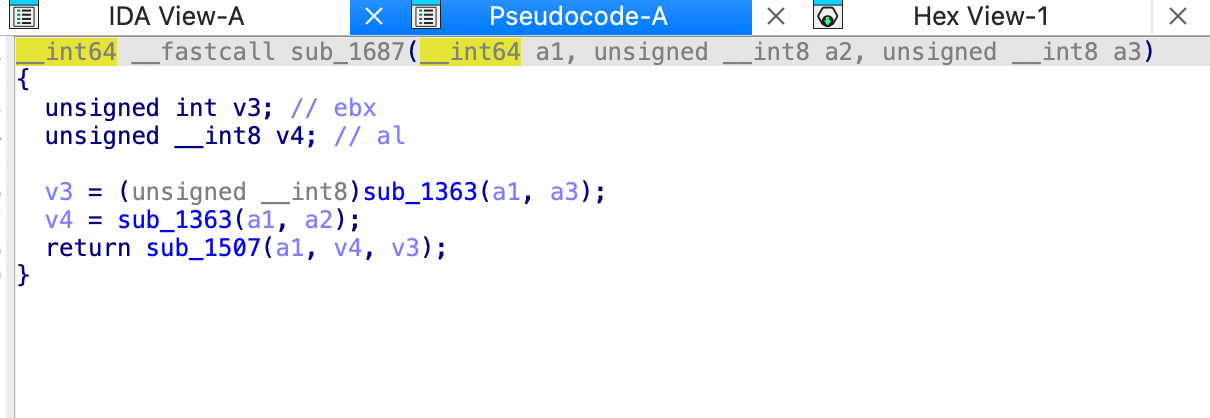
0x1687这个函数,首先,传入了a1,16,2,这个16应该就是下标索引,2的话就是2里面的值,也就是说a1[88]=222,以此类推8个字节分别是222,86,175,83,92,217,104,188
Level14.0
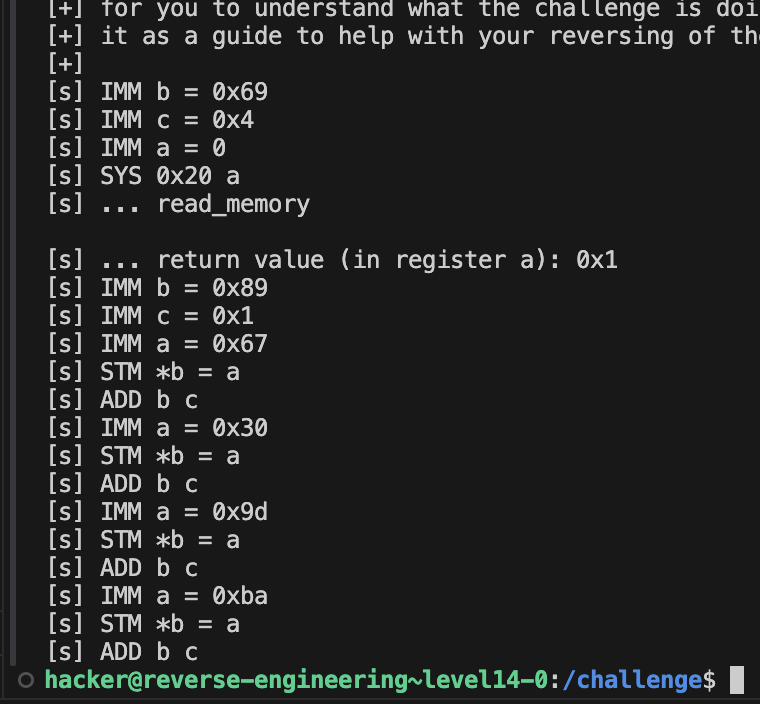
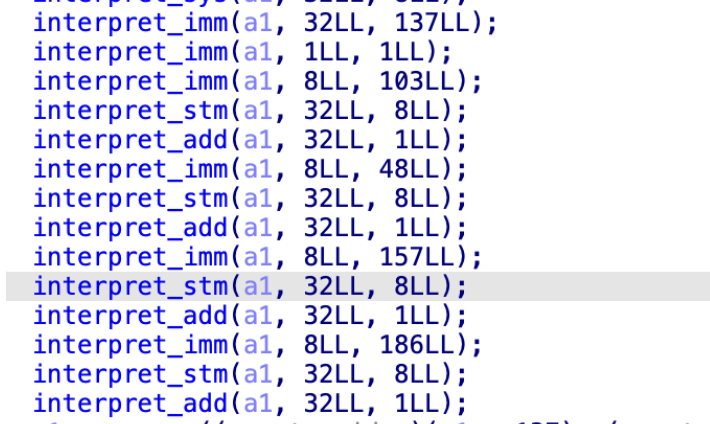
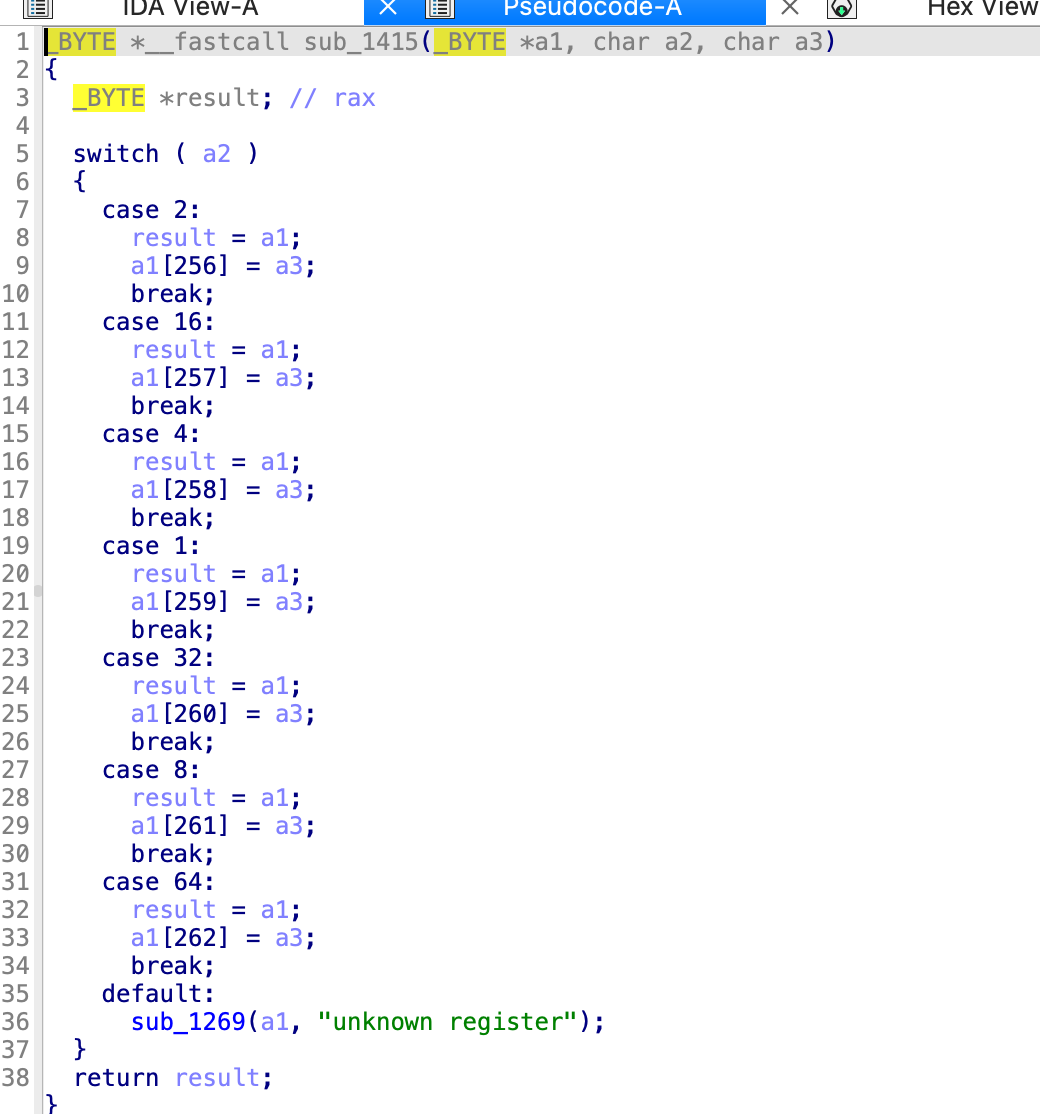
imm的作用已经知道了,现在看一下sys的作用,第一个sys传进去了a1,32,8,能看出来32就是最开始的b,而8是a,那就是说传入了b和a,
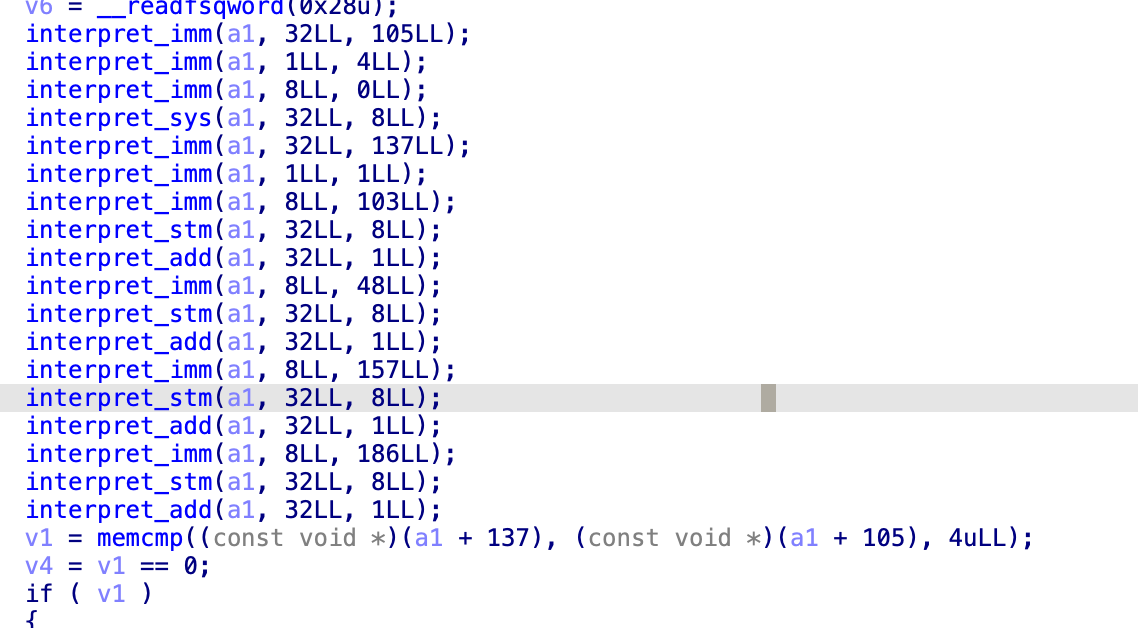

在sys里面,有一个选择结构,是根据a2进行选择的,32是0x20,所以是一个读取操作,a1[258]就到了main函数的v4的第三个字节,但是整个v4都是0啊,没太看懂,
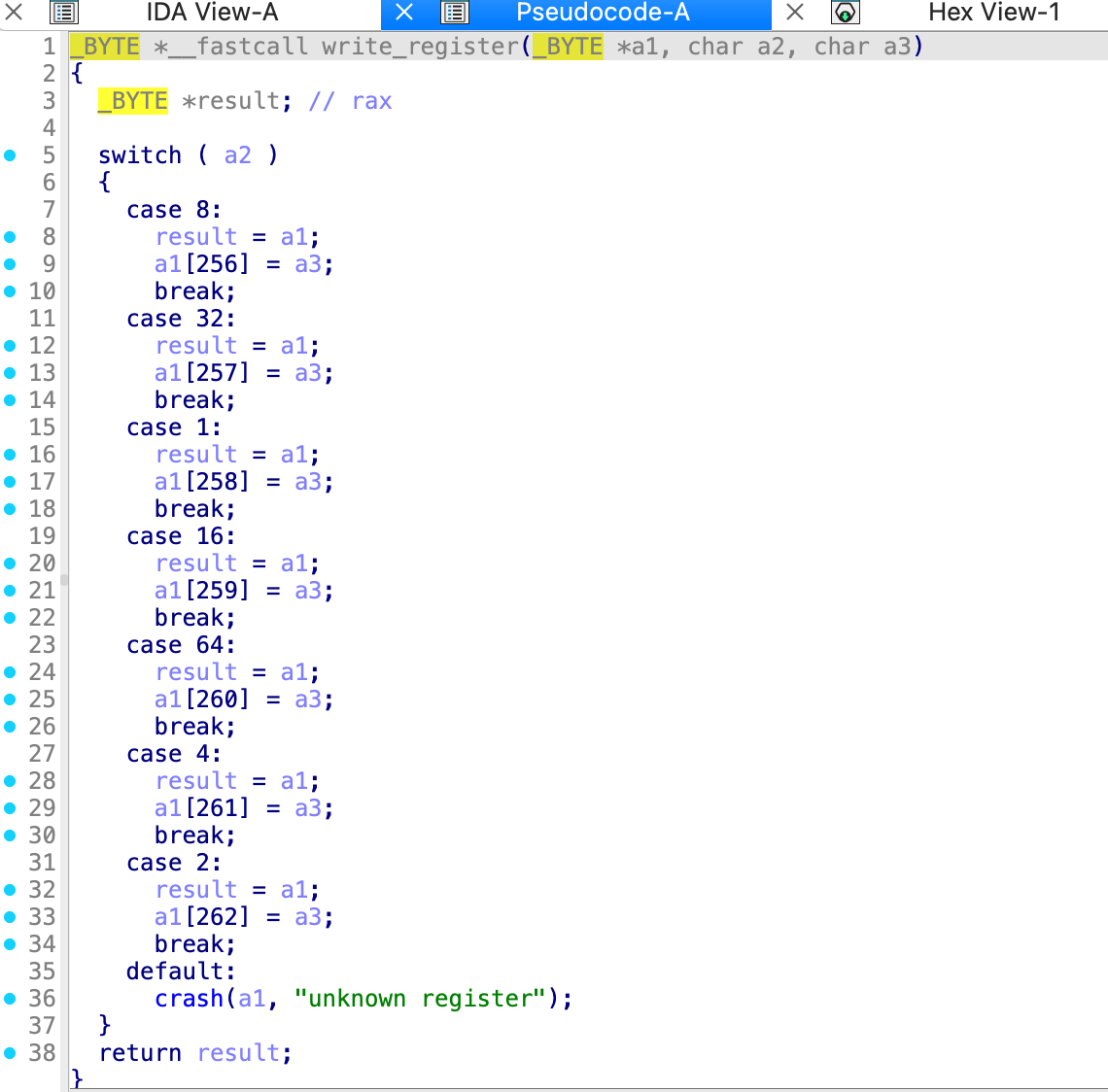
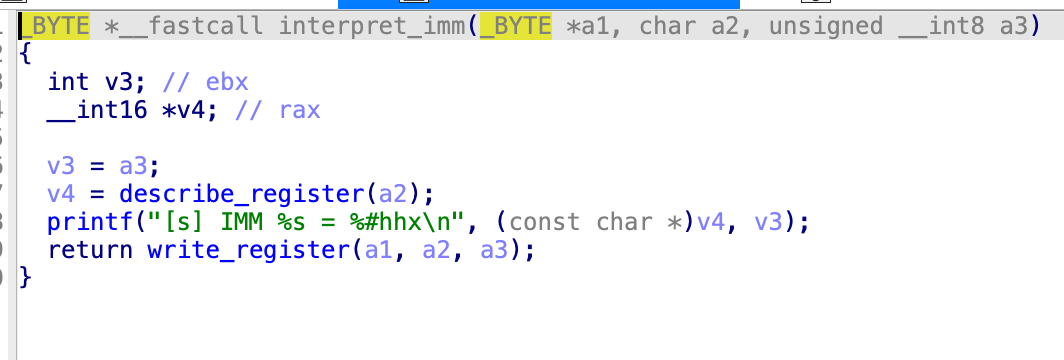
Write_register(a1,8,v9)
但是通过return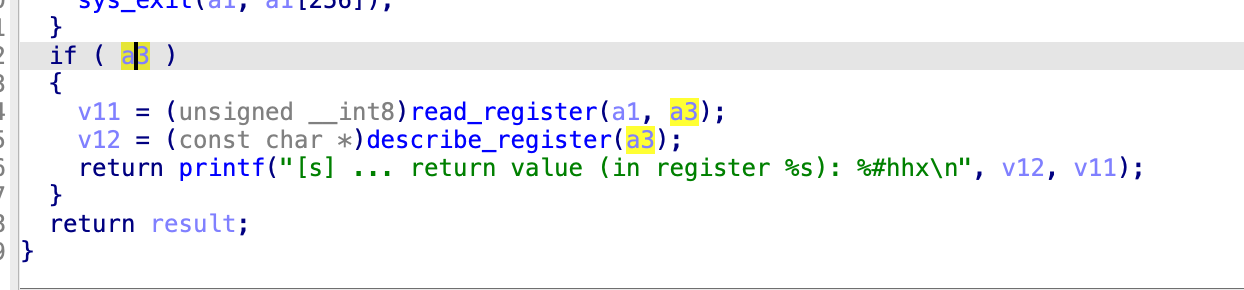
能看到,如果a3不为0的话,这里a3就是8,那么就会执行这个,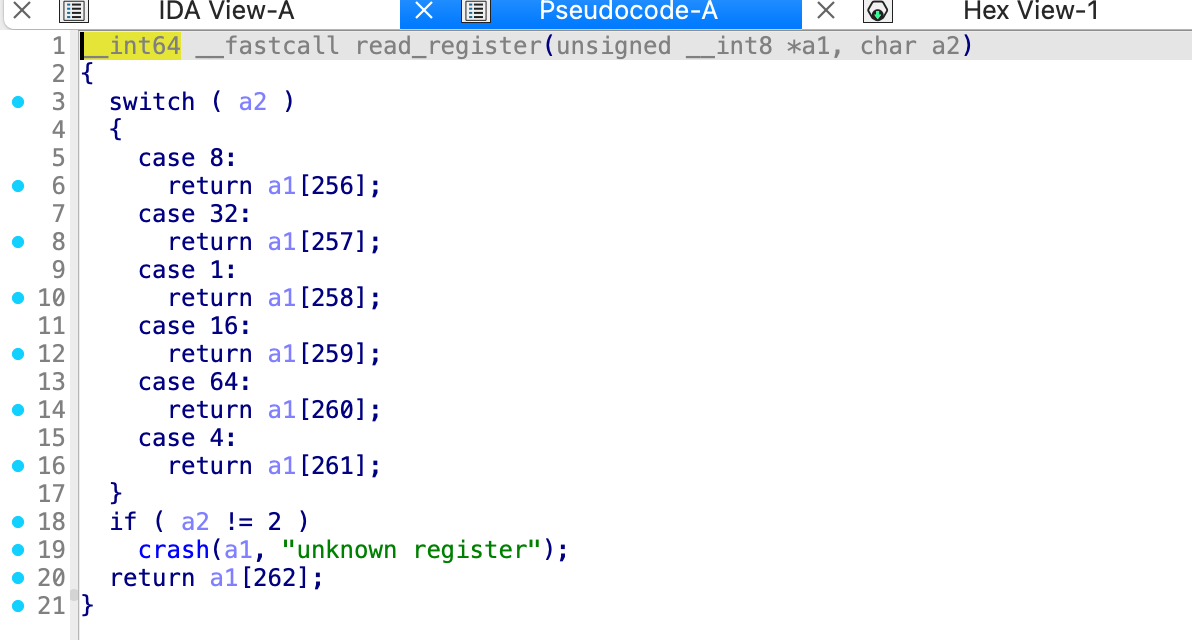
return了a1[256]给v11,v12是
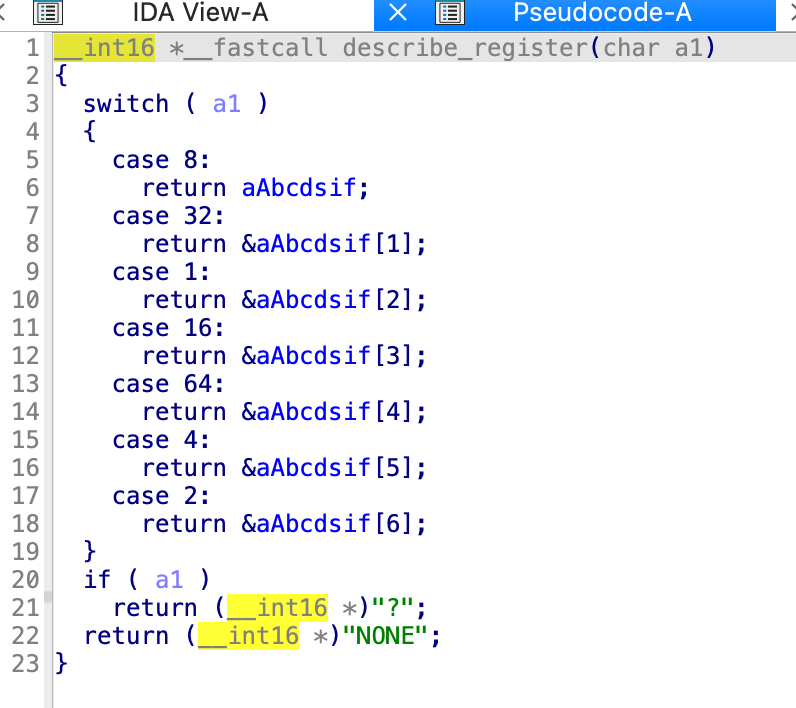
应该就是一个字符,这里也就是a,最后打印出来的就是
对应的0x4的值是a1[256]
回到比较结果

比较了四个字节,比较的是137和105开始的四个字节
137开始的四个字节是0x67,0x30,0x9d,0xba
看了半天,结果直接输入就行了,我服了,那我在分析nm呢,那从结论返回推过程,看一下怎么输入到a1+105的,首先a=0,b=105,c=4,
之后sys (0x20,a)
原来如此,我明白了,前面imm赋值过程中其实就改变了那几个数,这下就明了了,
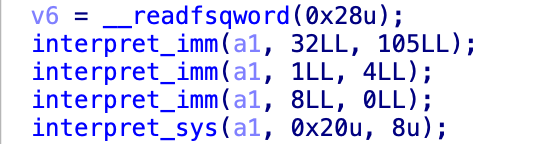
首先第一个imm,
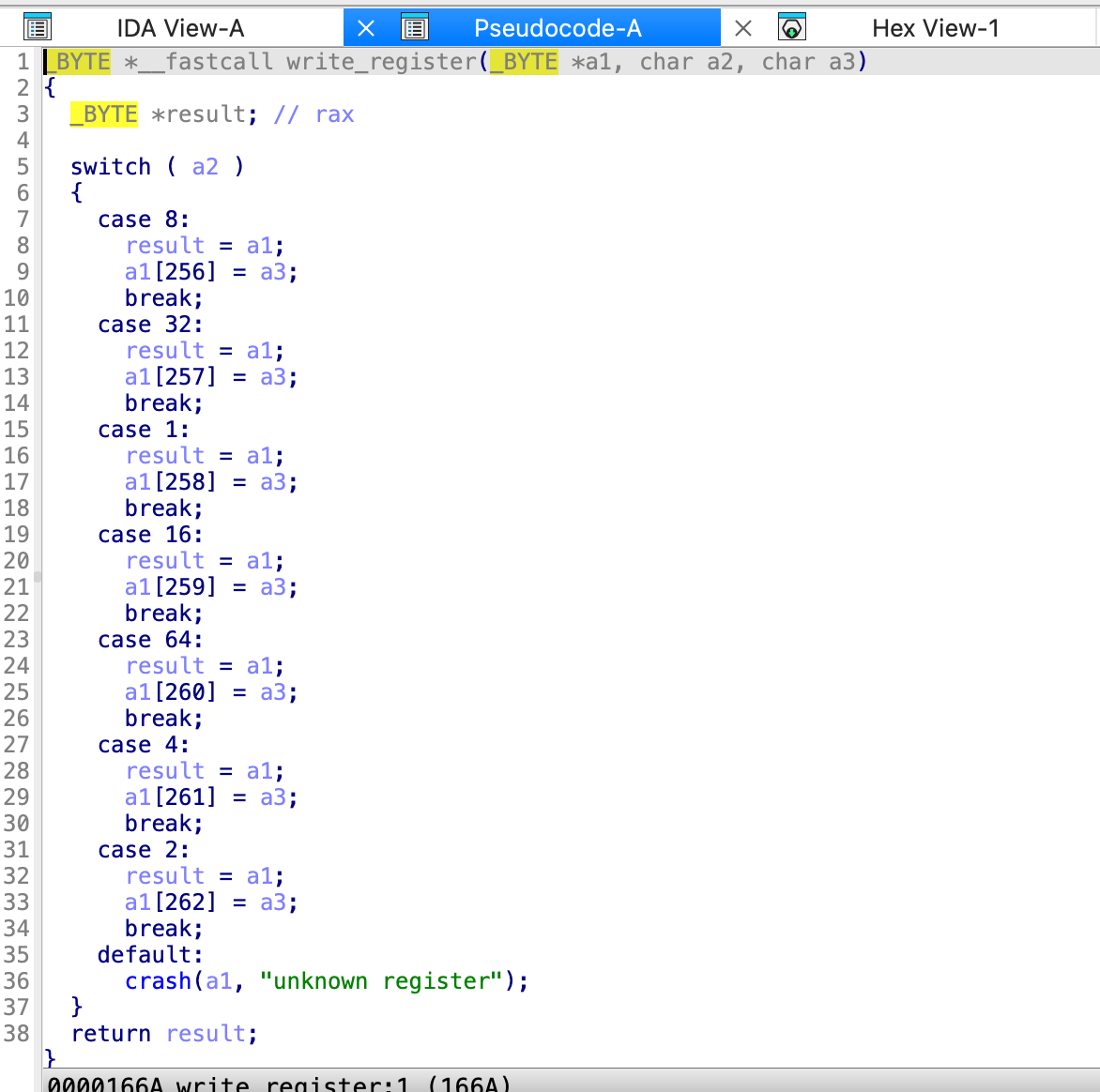
32 ,105,那就是将a1[257]变成了105
1 ,4 就是将a1[258]变成了4
8,0 就是把a1[256]变成了0,接下来再进入到之前的流程

sys的read过程中,v5=4,然后256-105>4,所以if并不触发,之后就是v6=sys_read,相当于read(0,&a[105],4)读取了4个字节,他妈的,分析完毕!结束!win!
level14.1